PDFをOCRでスキャンする方法
目次
PDFelementのPDF OCR(光学式文字認識)機能なら、スキャンPDFや画像ベースのPDFを完全に編集可能・検索可能なドキュメントへ高速変換できます。このPDF OCR技術は画像やスキャンページ内のテキストを自動認識し、データ抽出・編集・検索を実現します。
さらに、強力なOCRツールでドキュメント全体またはエリア指定のPDFスキャンが可能です。PDFにOCR(テキスト認識)を適用するステップは下記をご覧ください。
PDF全体のOCR処理
ステップ1.ドキュメントを開いたら、画面左のサイドバーから「ツール」をクリックし、展開メニューで「OCR処理」を選択します。

ツールを開きOCRを選択
ステップ2.次の画面で希望の言語とページ範囲を選択し、「高度な設定」を展開して「編集可能なテキスト」にチェックを入れます。検索のみの場合は「画像内検索可能テキスト」を選び、「適用」をクリック。編集できる新しいPDFが別ウィンドウで作成されます。
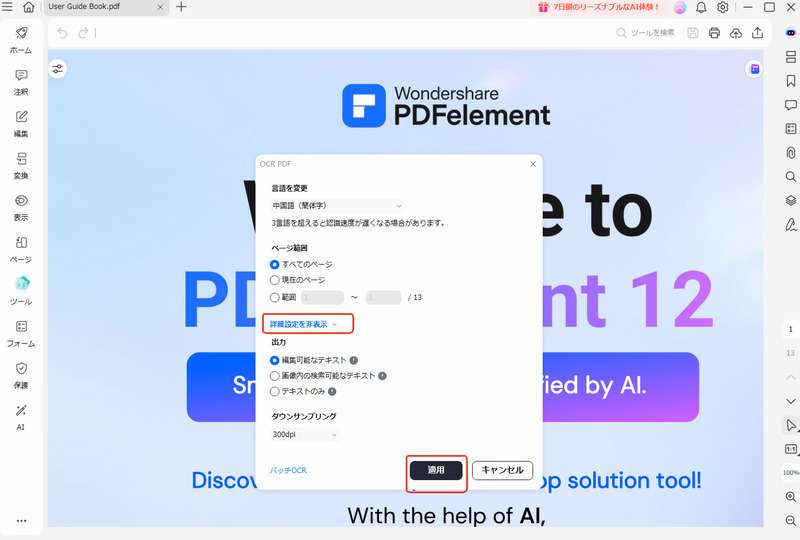
言語選択し適用する
特定エリアのOCR実行
ステップ1.最初にPDFを開き、左サイドバーから「ツール」を押します。次に展開リストから「OCRエリア」をクリックして選択します。

OCRエリア指定を選択
ステップ2.OCRをかけたいページ範囲をカーソルでドラッグして指定し、左パネルから日本語などの言語を選んで「認識」ボタンを押します。指定エリアが素早く編集・検索可能な状態になります。

範囲選択しOCR実行

