

OCR技術で紙の文書をデジタル化
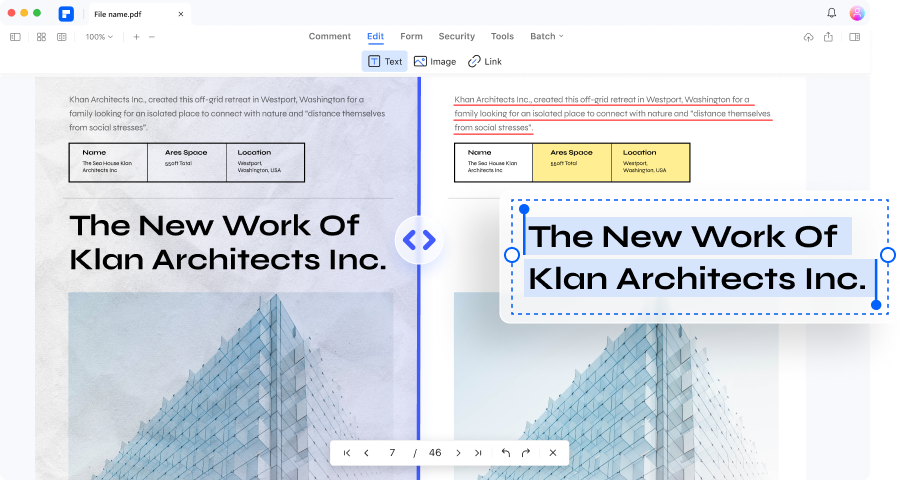
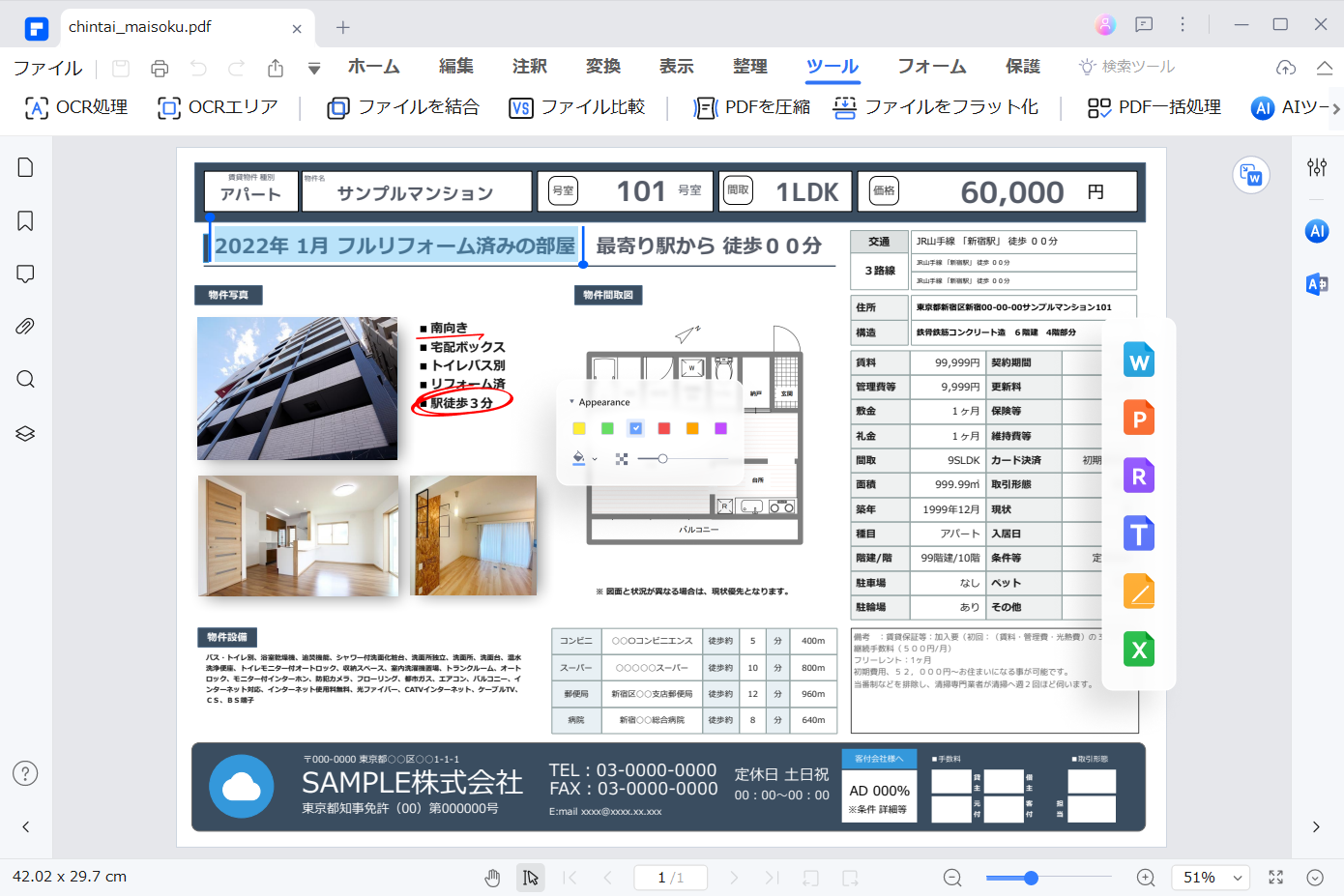
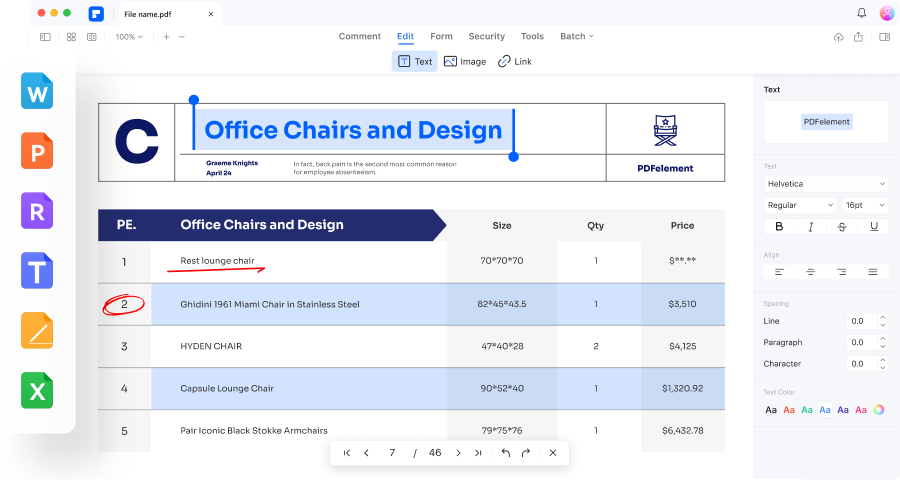
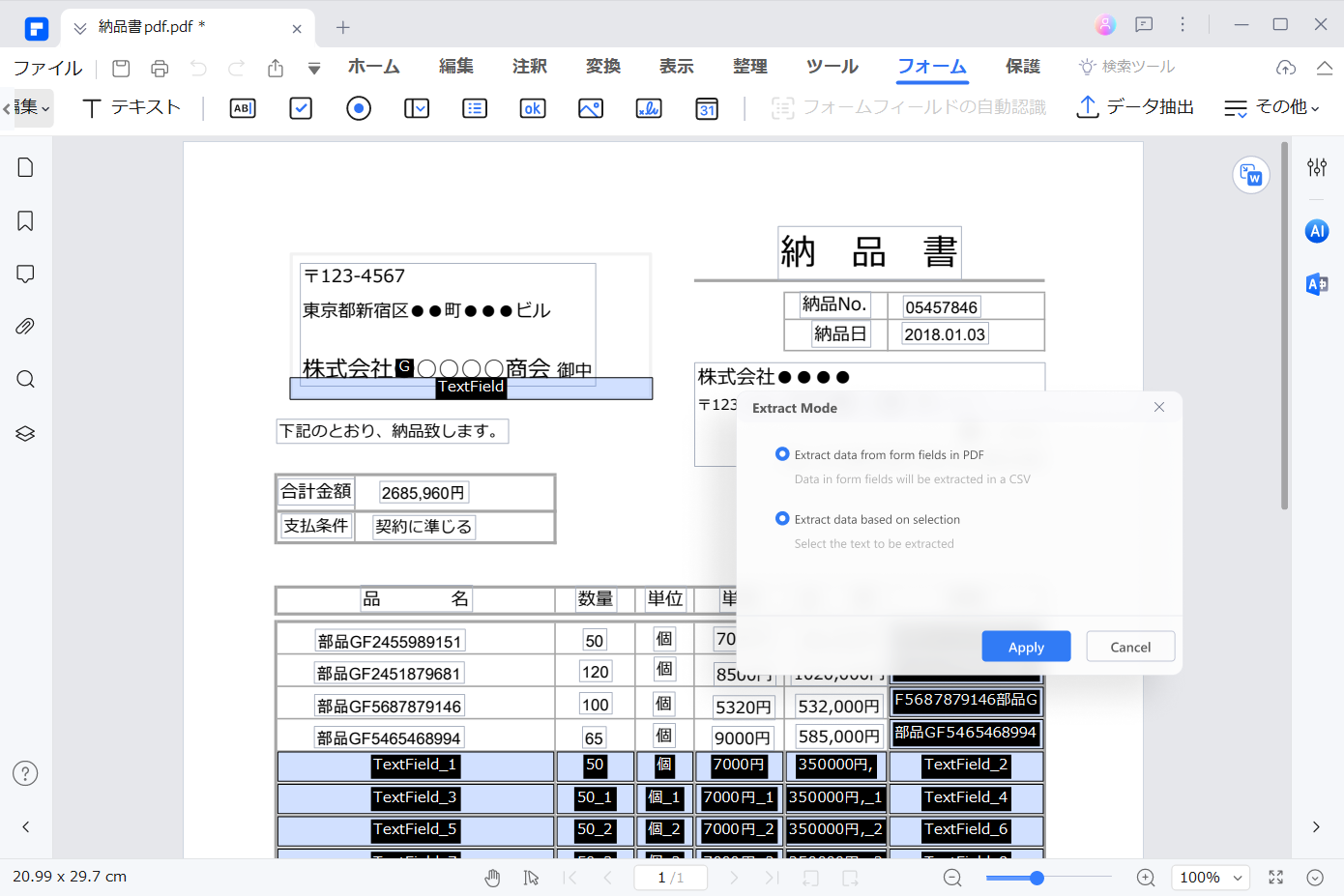












スキャンしたPDFを編集可能なPDFに変換する方法は?



最新バージョンをダウンロード|安全性確認済み
よくある質問
-
OCRとは何ですか?
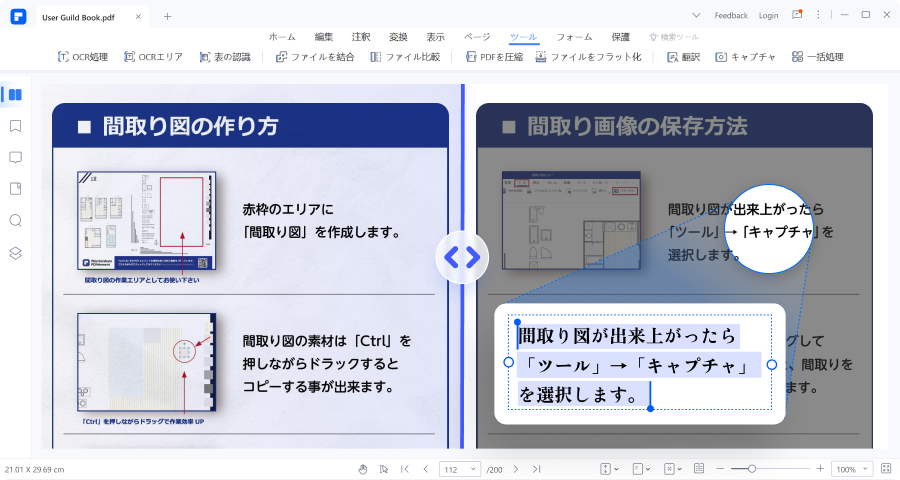
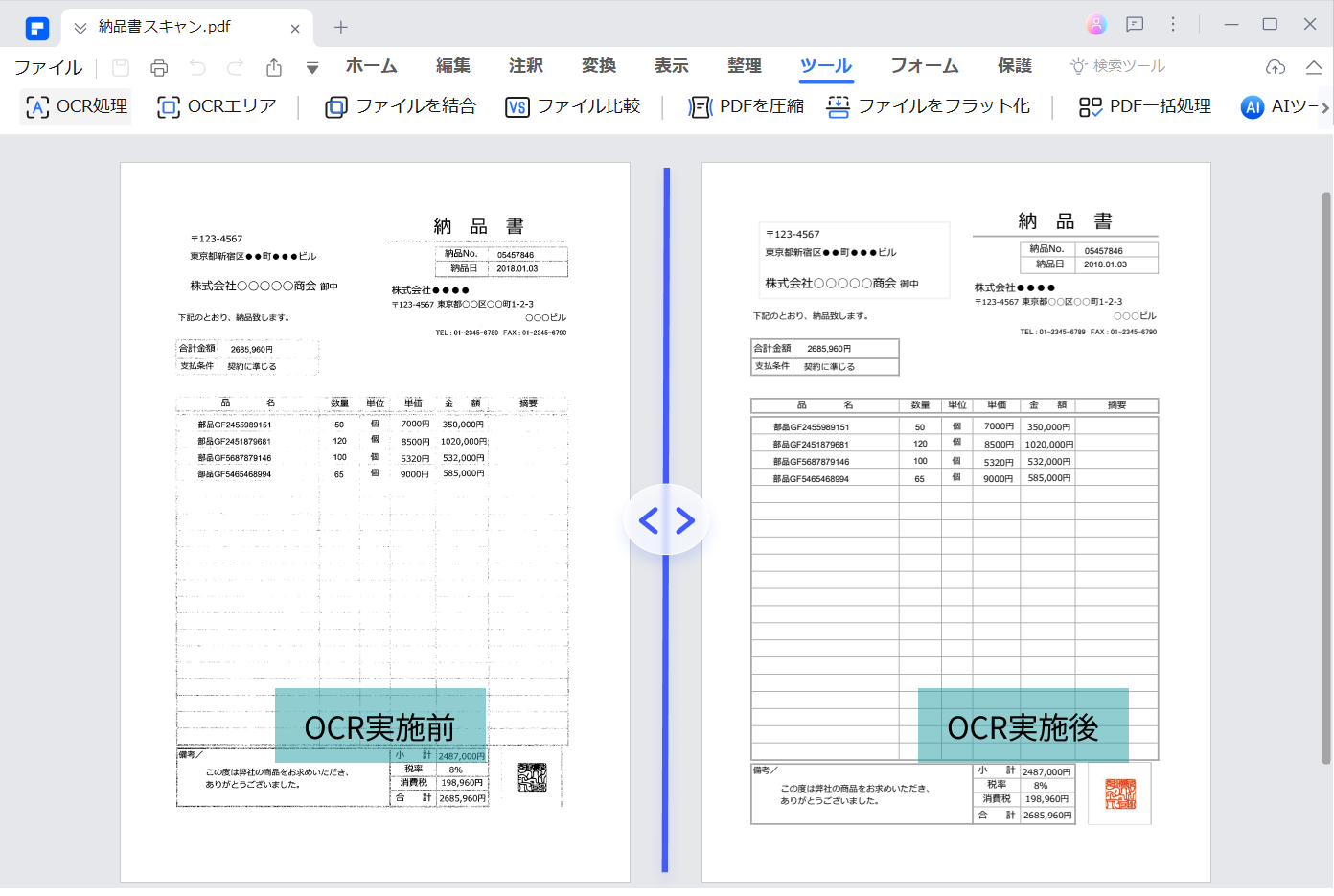
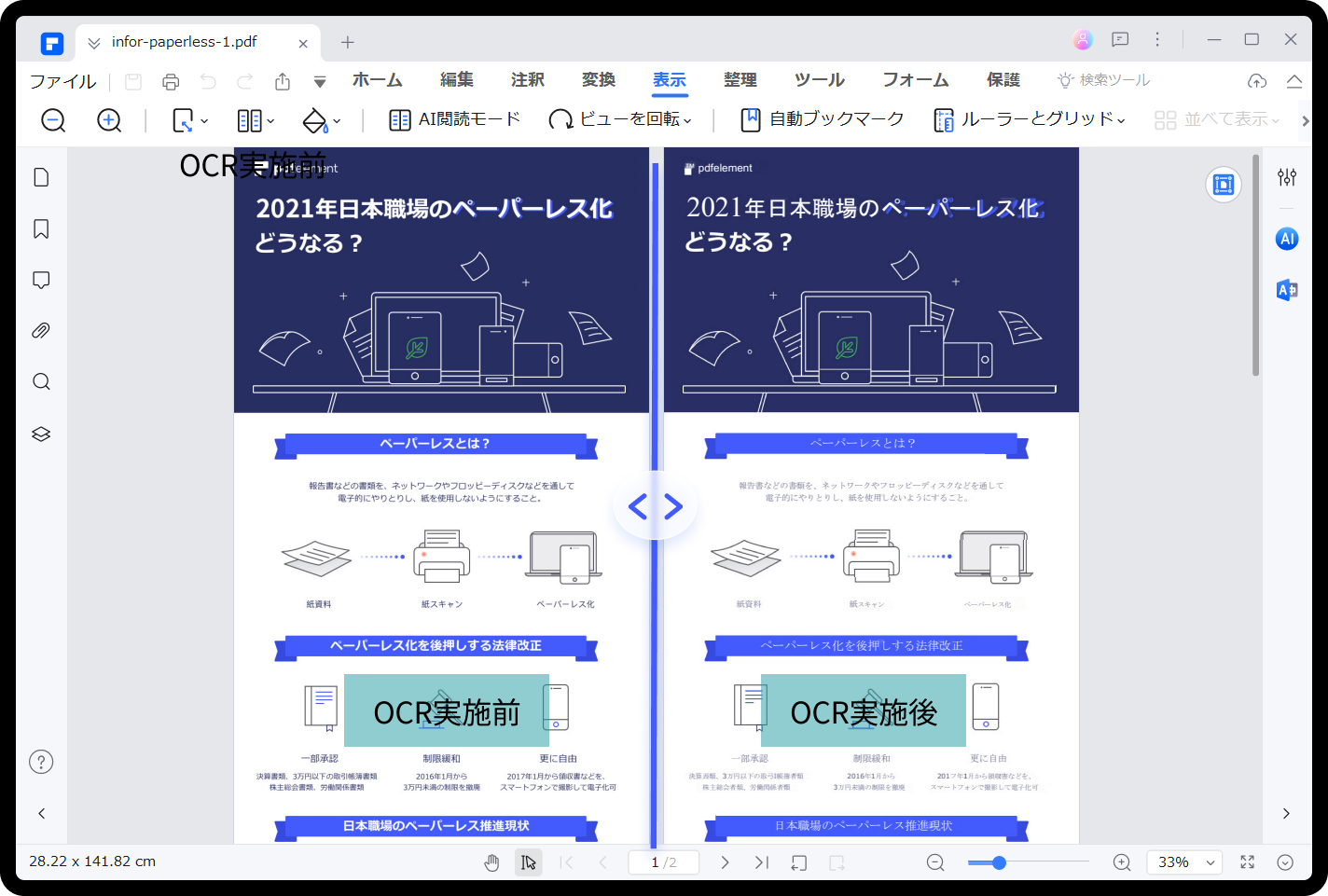
OCR (Optical Character Recognition) は、画像やスキャンした文書上のテキストを認識するためのレイアウトスキャナです。あらゆるキャプション付き画像を、読み取り可能なデータ、検索可能なデータに変換することができます。もちろん、テキスト、印刷された文書、手書きの文書も含まれます。多くの企業や個人のユーザーが、ID、パスポート、請求書などの文書から編集可能なテキストをスキャン、分析、抽出するためにOCRを使っています。
-
PDFを検索可能にする方法は?
Wondershare PDFエレメントを使えば、迅速かつ簡単に編集可能なテキストにPDFファイルを変換することができます。操作方法は以下のようになります。
ステップ1:WindowsまたはmacOSのPDFエレメントをインストールします。
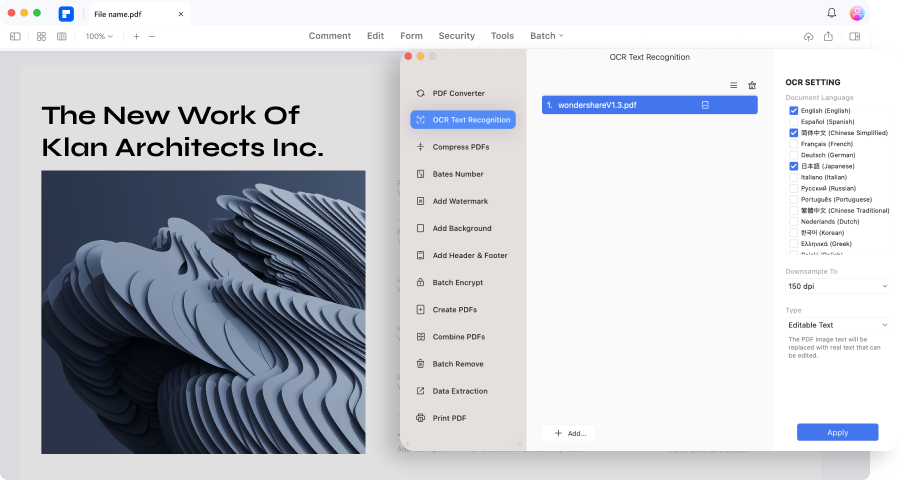
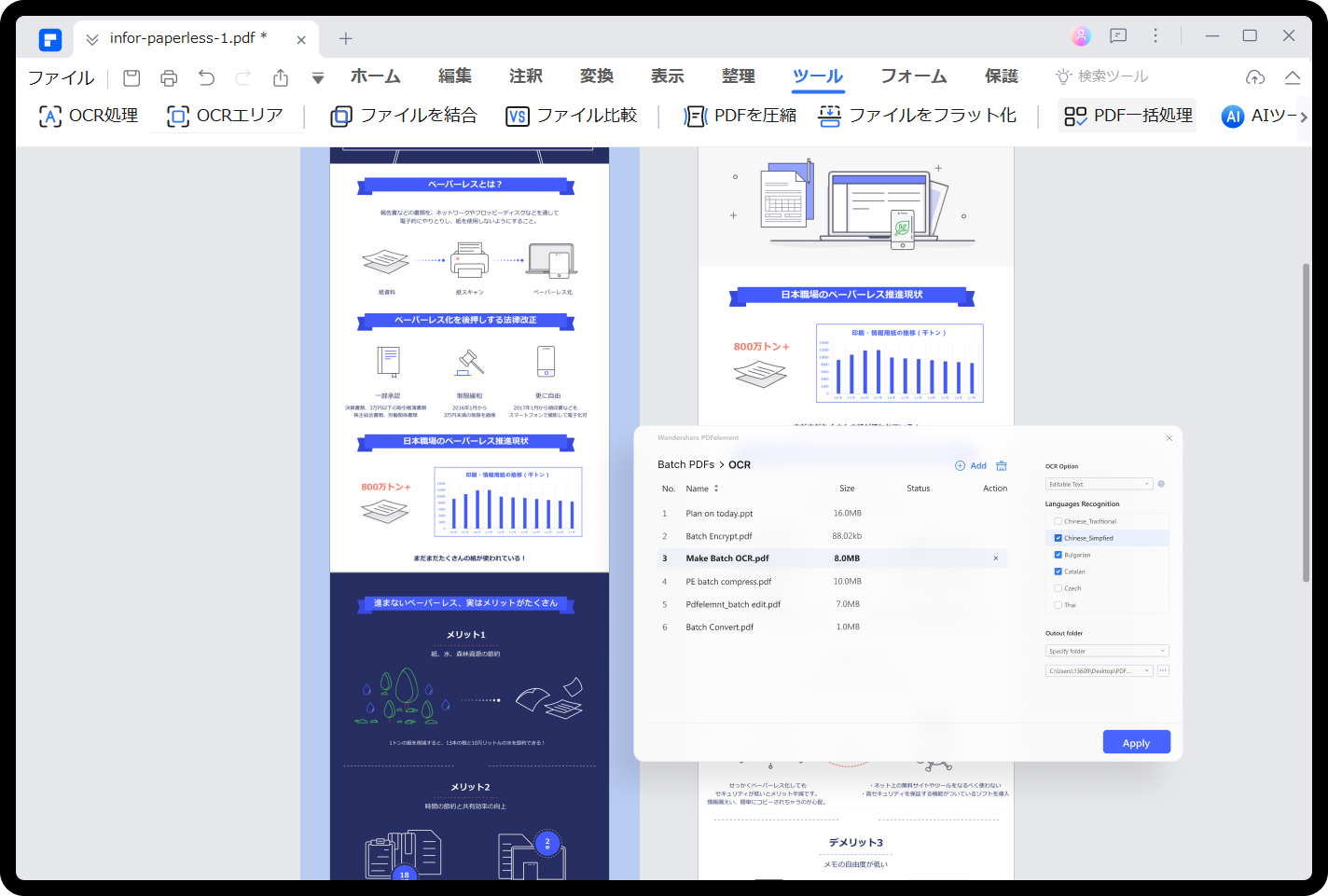
ステップ2:次に、OCR PDFをタップします。"画像内の検索可能なテキストにスキャン "としてスキャンオプションを設定するポップアップウィンドウが表示されます。また、[適用]をクリックする前に、ページ範囲と言語認識を選択することができます。
ステップ3:PDFエレメントは、PDF文書をスキャンして分析します。今より多くのテキスト、画像オーバーレイ、リンク、署名、フィードバックなどPDFを編集することに進めます。
-
スキャンしたPDFをWordに変換するにはどうすればよいですか?
PDFエレメントを使うと、スキャンしたPDFを編集可能なWordに変換することができます。方法は以下のようになります。
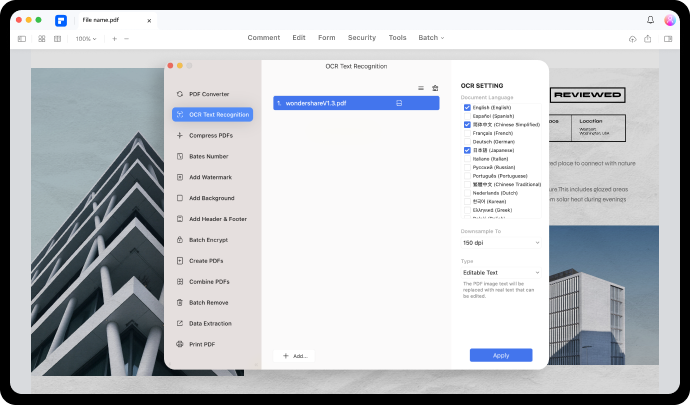
ステップ1.PDFエレメントを開き、クリックしてOCR PDFをアップロードし、それからOCRを実行します。
ステップ2.PDFファイルをスキャンして編集した後、上部のメニューバーでクリックして変換ボタンをクリックします。Word、Excel、テキスト、PPTなど複数の出力オプションが表示されます。このケースでは、Wordを選択します。
ステップ3.ファイル名を付けて、保存先のパスを選択し、PDFに変換します。とても簡単です。
-
無料のOCRソフトがありませんか?
オンラインにインストールする多くのOCRプログラムがあります。しかし、これらのOCRサービスのほとんどは無料ではありません。無料のOCRサービスを探しているなら、Wondershare PDFエレメントをインストールし、スキャンした画像を含むすべてのPDFファイルをOCRします。PDFエレメントは、OCRファイルをスキャンして編集するための特別なOCRのスキルを必要としないので、驚くほど簡単です。ぜひ試してみてください。