 OCRソフトの紹介
OCRソフトの紹介 スキャン&PDF化
スキャン&PDF化 スキャンPDFの編集
スキャンPDFの編集 スキャンPDFの変換
スキャンPDFの変換 画像化のPDFデーダ抽出
画像化のPDFデーダ抽出 OCR機能活用事例
OCR機能活用事例OCRとは、自動文字認識のことでスキャンした画像データから自動で文字を識別してテキスト化することができる機能です。OCRは、さまざまなソフトウェアで使用できるもので文書ファイル形式のPDFを取り扱うAdobe Acrobatでもその機能が搭載されています。しかしAdobe Acrobatを使わなくても高機能なOCRを搭載したPDF編集加工するソフトウェアは多く存在しています。
目次:
Part 1. OCRとは?OCRの仕組みと用途について
OCRの仕組みについて
OCRとはOptical Character Recognition/Readerの略で日本語では光学的文字認識と呼ばれます。これらは画像データにある文字を識別してテキスト化(文字コード化)するものです。仕組みは手書き文字認識と同じで一定の範囲にある線を識別して最適な文字コードを探し出して変換するというものです。活字体で書かれたものであれば、ほぼ完全にテキスト化することができますし、手書きのものも精度が上がっており、またコンピューターの性能が向上しているので、わずかな時間で作業を完了させることができます。
OCRの用途について
用途としては文書をテキスト化するさいの補助として使われます。OCRが登場する以前のテキスト化は人力ですべての作業を行ってきましたが、これをソフトウェアで補助することでその作業の度合いを大幅に減らすことができます。またpdfファイルでは、必ずしもすべてをテキスト化するのではなく検索時だけ適用されるものがあり、この場合には画像ファイルによる文章ですが、検索するさいにはocrによって得られたデータを用いて行うので、画像の文書であっても、検索機能を使って目的のページを探すことが可能です。
Part 2. PDFを使うメリットは?PDFで出来る機能とは?
PDFを使うメリット
PDFは、Portable Document Formatの略で、アドビシステムズが発表している文書規格です。目的としてはソフトウェアやハードウェア、またオペレーションシステムによる違いに関係なく文書を確実に表示したり、また印刷するための機能を有しています。現在、国際標準化機構(ISO)によって管理されており、世界中で使われており数多くのソフトウェアで対応しています。基本的に閲覧だけであればAdobe Acrobat readerと呼ばれるソフトを使います。Adobe Acrobat DCは編集加工ソフトで無料で試用することができます。
PDFで出来る機能
基本的な考え方としてはあらゆるハードウェアやソフトウェアでも規格通りに作られたソフトウェアを使えば正確にその文書を見ることができるというものです。このためページ印刷に特化しておりPDF形式でマニュアルや申請書を作成して公開しているところも多くあります。圧縮機能があるのでファイルサイズを小さくすることができますし、パスワードを設定することで自由に閲覧できないように制限するといった機能も付与されているものです。それに電子署名にも対応しているので公文書の形式としても広く使われています。また文書を作成する一定の機能を有しているソフトも多く、その中の便利な機能がOCRです。
Part 3. PDFelementを使ったOCR
PDFelement(PDFエレメント)は、PDF編集や加工を簡単に行えるソフトウェアです。多様な機能が搭載されていますが、そのひとつにOCR機能も実装しています。PDFelementの使い方は簡単で画像を読み込ませ実行すればテキスト化が完了です。これによりテキストの検索やコピペが可能です。それにテキストの編集や挿入が出来ますし文字のフォントやサイズを変更することもできます。また文字以外の画像もサイズごとに切り分けて保存されるので、ロゴだけを抽出するといった使い方もできます。
PDFを編集加工するのであれば、ocrの機能が搭載されているものを選ぶことで紙媒体による文書を読み込ませるさいの作業負担を大幅に軽減することができます。それにテキスト化することによってPDFファイルから目的のワードを検索することができますし、読みにくい文書を読みやすく編集するといった面でも便利です。
Part 4. PDFelementのOCR機能でスキャンしたPDFを編集可能なファイルに変換する方法
日常の仕事にデジタル文書形式のPDF、Webサイトや取引先から入手したPDFはいつも困るでしょう?また、新聞・雑誌の多くは、単に文字が同じ並び方で並んでいるのではなく、段組みやコラムがあり、表や図があり、標題があります。閲覧・印刷用だけに困るのはそのデータの再利用でしょう?この場合再利用したい時はどうしたらよいでしょうか?PDFelement(PDFエレメント)をお勧めします。その中のPDF OCR機能で従来画像として出力されていた文字を、編集可能な文字として出力可能です。(*PDFelementの他にはPDF OCRツールもあります、より多くの無料PDF OCRツールについて詳しくは>> )
PDFelementのOCR機能を利用することで、フォントが埋め込まれていて文字コードがないPDFからも文字を認識して変換することが可能です。今回は、「PDFelement」のOCR機能で画像化のPDFデーダ抽出・変換する方法をご紹介いたします。
Step1. 画像形式、あるいはスキャンされたPDFファイルの読み込む
PDFelement(PDFエレメント)をダウンロードして、インストールしてください。
起動後、PDFをドラッグ&ドロップでこのソフトのウィンドウに落とすか、『開く』ボタンからファイルを選んで、変換したい画像化のPDFファイルを選択・登録できます。複数のPDFファイルを一括で読み込みできます。
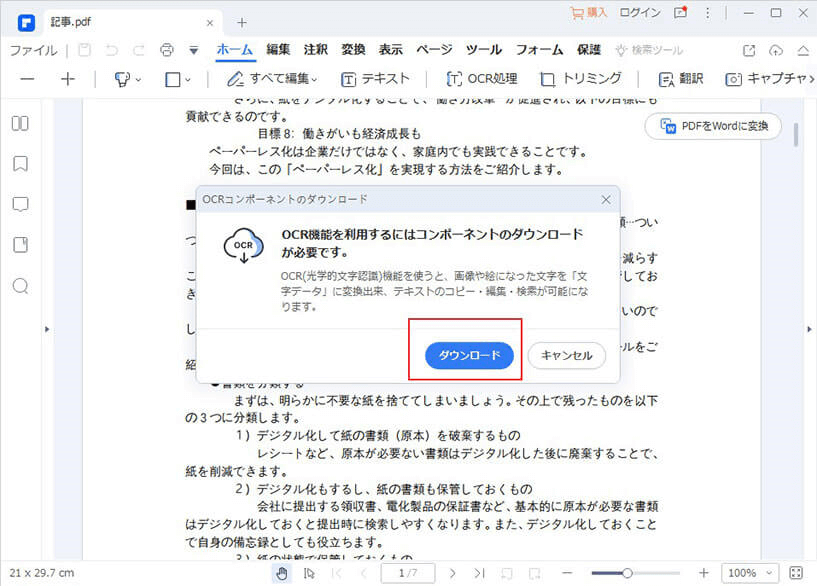
Step2. 「PDFelement」とOCRプラグインのインストール
「ツール」→「OCR処理」をクリックすると、OCRプラグインのダウンロード案内が表示されます。OCRプラグインをダウンロードしてインストールしてください。
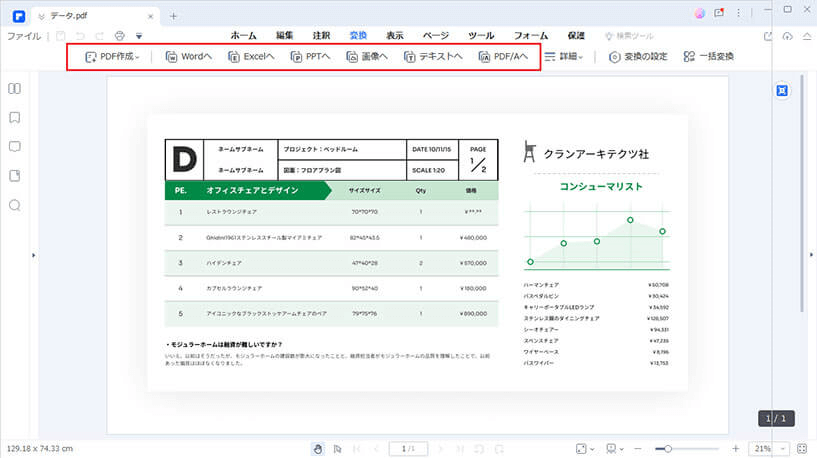
Step3. 画像化のPDFデーダを出力する前に、出力形式とOCR機能を設定
変換する前に、PDF OCR設定を行うのが必要です:出力形式を選択した後、出てきたウィンドウに「設定」をクリックして、「OCR機能」→「スキャンされたPDFファイルのみ」を選択し、「OK」をクリックします。
「変換」タグから、「Word形式に」または「他の形式に」で出力ファイル形式を選びます。*スキャンしたPDFファイルを編集可能のWordに変換する方法について詳しくは>>
Word、Excel、PowerPoint、画像、EPUB、HTML、TEXT、RTFなどで出力することができます。*OCR機能でスキャンしたPDFを編集可能のエクセルに変換する方法について詳しくはこちら>>
変換したいファイル形式をクリックすれば相応形式に変換してくれます。
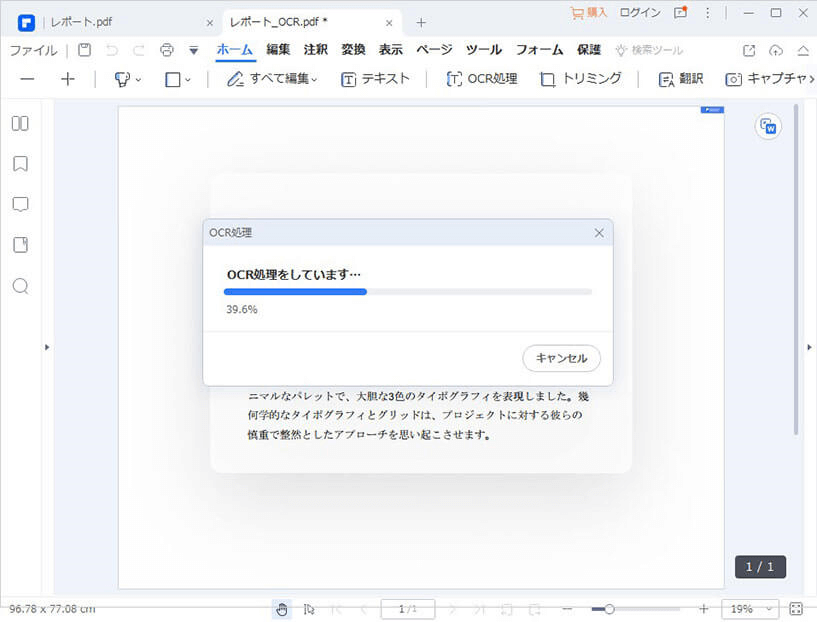
Step4. 画像化のPDFを他の形式に変換開始
PDF OCR設定が終わったら、「適応」をクリックして、変換が始まります。
数秒後にファイルが変換完了ということを知らせる画面が表示されます。画像化のPDFから変換されたファイルは編集可能になります。
以上はOCR機能付きのPDF編集・変換ソフトで、画像化のPDFを編集う可能のファイル形式に変換する操作手順でした。簡単でしょう。
PDFelement(PDFエレメント)は文字認識可能なOCR機能を付き、文字が画像化されてしまったPDFに対しても、画像からテキスト情報を抽出して、PDFを各形式ファイル(Word、Excel、PowerPoint、Epub、HTML、Text、画像jpegなど)への高精度変換も可能です。今すぐこのPDF ocrツールを無料でダウンロードして試してみましょう。








役に立ちましたか?コメントしましょう!