OCRでPDFをテキスト化する手順を徹底解説|PDF文字読み取りガイド
「PDFの文字をコピーできない」「スキャンPDFを編集したい」と思ったことはありませんか?
こういった問題はOCRを活用して、PDFからテキストを抽出することが可能です。
OCRとは「光学文字認識」のことで、画像などに含まれる文字をデジタル上で使用できるテキストデータに変換する技術です。
スキャンした文書の文字データをコピーや編集することができるため、仕事の効率化に役立ちます。
そこで本記事では、OCRでPDFをテキストデータ化し、効率的にデータを扱う方法について解説します。
今すぐOCRでPDFからテキストを抽出したい方は、ぜひチェックしてみてください。
1.PDF が「画像PDF」か「テキストPDF」か見分ける方法
OCRでの処理をする前に、PDFが「画像PDF」か「テキストPDF」か見分けることが重要です。理由は、PDFデータの種類によって採用する処理方法が異なるからです。
これらの違いは、PDF内の文字をPC上でコピーできるかどうかで簡単に見分けることができます。コピーができる場合は「テキストPDF」、できない場合は「画像PDF」です。
テキストPDFは文字情報がコードとして保存されているのに対し、画像PDFはスキャンされた文字が画像として保存されています。
2. OCR を使って PDF からテキストを抽出する方法(PDFelementの使い方)
PDFelementとは、Wondershareが提供するPDFの編集・変換・作成などを行うための多機能のソフトウェアのことです。
WindowsやMac、スマートフォン・タブレットでも使用可能です。無料版で7日間〜14日間まで使用することが可能です。
また、有料版では一括でPDFをまとめて編集したり、表やデータを簡単に取り出したりする機能が使えます。
以下から、PDFelementでOCRを使用して、PDFからテキストを抽出する方法を見ていきましょう。
2-1 PDFからテキストを抽出する手順
ここでは、4つのステップに分けてPDFからテキストを抽出する手順を解説いたします。
Step1.「PDFelement」の無料試用版をダウンロード・インストール
下記のボタンをクリックすると、ソフトを無料ダウンロードすることが可能です。WindowsとMac両方とも使用できます。また、スマートフォンやタブレットでも対応可能です。ダウンロードしたファイルをダブルクリックすると、インストールは完了です。


![]() プライバシー保護 | マルウェアなし | 広告なし
プライバシー保護 | マルウェアなし | 広告なし
Step2.スキャンしたいPDFを選択する
次に、下記の写真からスキャンしたいPDFを選びます。
選ぶ際は、下記の画像左上の「PDFを開く」をクリックしましょう。
Step3.OCR処理を行う
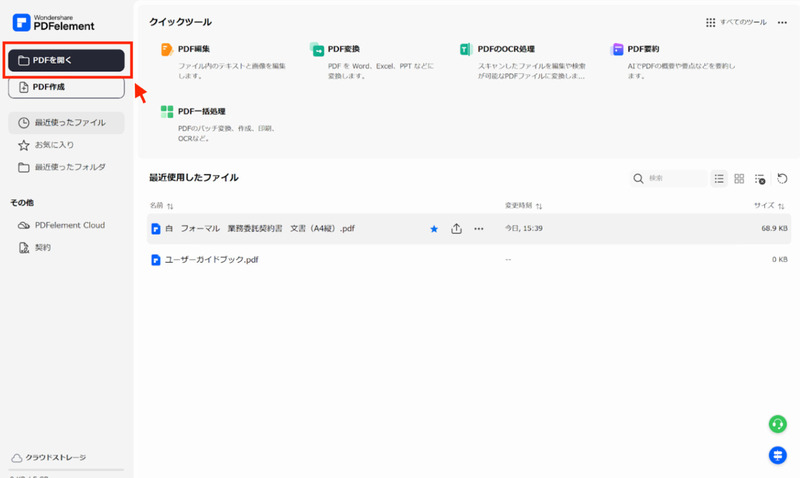
文書を選び終わったら、画面上部の「OCR処理」のボタンをクリックします。
すると下記の画面が出てくるため、「適用」をクリックしてください。
Step4.テキストデータの抽出が完了
以上の操作でOCRが適用され、文字のコピーや編集が可能になります。
2-2 複数ページ・選択範囲でのPDFテキスト抽出方法
複数ページ・選択範囲でのPDFテキスト抽出方法について説明します。
1枚だけであれば無料試用版で行うことが可能ですが、複数のページをOCRしたい場合はPDFelementのプロ版を購入することが必要です。
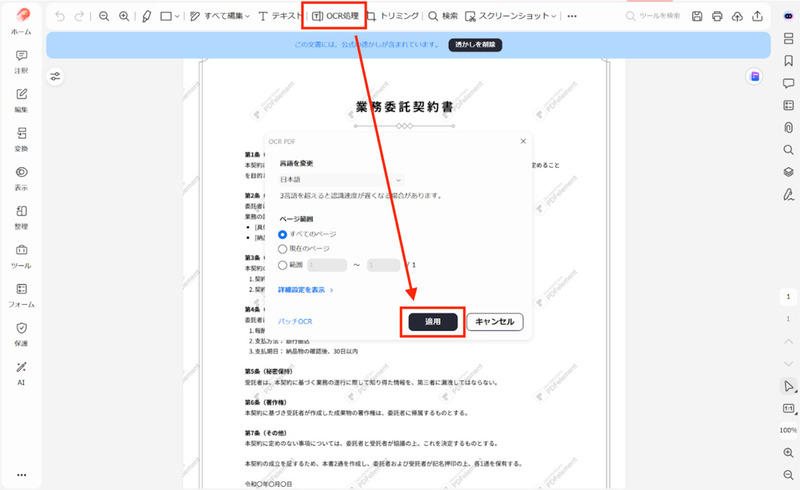
Step1.「PDF一括処理」を選択する
PDFelementのダウンロードがまだの場合は、下記のボタンをクリックしてインストールしましょう。WindowsとMac両方とも使用できます。ダウンロードしたファイルをダブルクリックすると、インストールは完了です。
![]() プライバシー保護 | マルウェアなし | 広告なし
プライバシー保護 | マルウェアなし | 広告なし
そして下記画像の画面から、「PDF一括処理」をダブルクリックします。
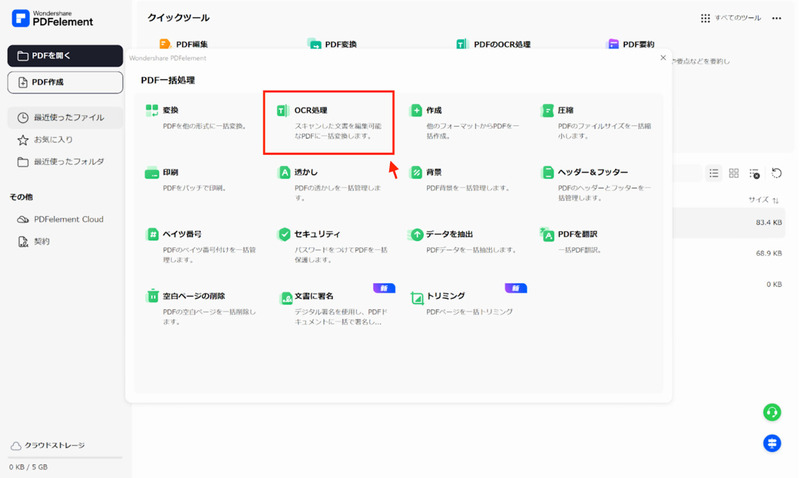
Step2.「OCR処理」を選択する
次に、下記の画面が出てくるので「OCR処理」を選択してください。
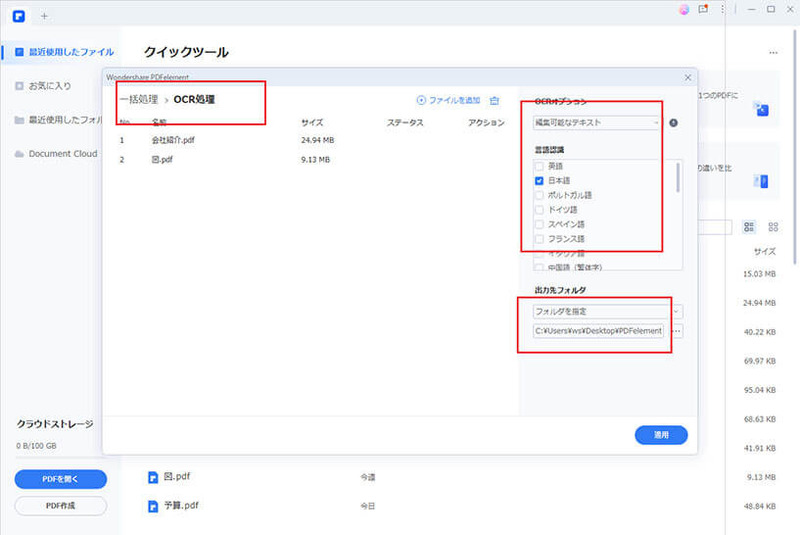
Step3.OCRの一括処理を行う
そして、OCR処理になっているか確認して、言語認識で日本語にチェックを入れます。
出力先フォルダを指定し適用を押すと一括OCR処理を行うことができます。
Step4.テキストデータの抽出が完了
以上の操作で一括OCRが適用され、文字のコピーや編集が可能になります。
2-3 詳細設定の出力形式の選び方
ここでは、編集可能なテキスト・画像内の検索可能なテキスト・テキストのみの3つにおいてそれぞれの説明と向いている場面について紹介します。
|
出力形式 |
特徴 |
向いている場面 |
|
編集可能なテキスト |
PDF内のテキストがマウスで 選択出来たりコピーできる形式 |
・文書をそのまま編集したい ・部分的にコピーや翻訳がしたい |
|
画像内の検索可能な テキスト |
スキャンされたPDFをOCRを使用してテキストが検索可能になった形式 |
・書類系をそのままの状態で保存したい ・法的文書の電子化 |
|
テキストのみ |
OCRで完全にテキスト化した形式 |
・内容をWordで再編集したい ・プログラムで内容を解析したい |
出力形式① 編集可能なテキスト
「編集可能なテキスト」とは、PDF内のテキストがマウスで選択出来たりコピーができるデータの出力形式です。
文書をそのまま編集したい時や、部分的にコピーをしたり翻訳したりするときに向いています。
出力形式② 画像内の検索可能なテキスト
「画像内の検索可能なテキスト」は、スキャンされたPDFをOCRを使用してテキストが検索可能な出力形式です。
証明書や領収書をそのままの状態で保存したいときや、法的文書の電子化をする時に向いています。
出力形式③ テキストのみ
「テキストのみ」は、OCRで完全にテキスト化する出力形式です。
画像資料の内容をWordなどで再編集したい時やプログラムで内容を解析したい時に向いています。

![]() プライバシー保護 | マルウェアなし | 広告なし
プライバシー保護 | マルウェアなし | 広告なし
3. OCRの精度を上げるコツ・注意点
では、OCRを使って画像データからより正確にテキストを抽出するにはどうしたら良いのでしょうか?
ここでは、OCRの精度をあげるコツをいくつかご紹介します。
方法① 解像度をあげる
高解像度にすることで文字の認識率が上がります。ただ、解像度をあげることによって生成までの時間がかかるので注意が必要です。
その対処法としては、全ての書類の解像度をあげるのではなく、文字認識の低い書類だけを使用すると良いでしょう。
方法② 向きの調整
スキャンする書類が傾いていたり読み込む文字自体が斜めになっていると認識精度が落ちてしまいます。
ソフトの中には傾き補正をしてくれるのでその方法を活用して傾きを無くしてからスキャンすることをおすすめします。
方法③ フォントや言語設定の確認
OCRで精度が上がりやすいフォントと下がりやすいフォントがあります。
上がりやすいフォントは、ゴシック体や明朝体などです。反対に下がりやすいフォントは手書き風なフォントや筆記体などです。
中でもゴシック体は、文字の太さが均一で形もシンプルなので読み取りに適しているフォントと言われています。
言語設定は、適切に行うことが重要です。言語によって読み取り方などが変わるため、スキャン時に日本語の文章であれば日本語設定にする必要があります。
方法④ 手書き文字や画像文字をより正確に抽出する方法
文字同士の間隔を広くとることや、スキャンを行う前にソフトに文字認識を設定することで、OCRの読み間違いを減らすことができます。
例えば、0(数字)とO(アルファベット)といったものが間違えやすい文字として挙げられます。
4. まとめ:PDFの文字を正確に読み取り・テキスト抽出するポイント
本記事では、PDFの文字を読み取ってテキスト化する方法について解説しました。
画像やスキャンデータからテキスト抽出を行いたい場合は、OCR(光学文字認識)機能を活用するのが効果的です。
Wondershareが提供するPDFelementなら、PDF OCR テキスト抽出機能を使って、PDFファイル内の文字を正確に認識し、コピー・編集・文字起こしまで簡単に行えます。
操作はシンプルで、テキスト抽出したいPDFを読み込むだけ。数クリックでPDF文字の読み取りからテキスト化までスムーズに実現できます。
また、PDF文字起こしを無料で試したい方にも最適です。出力形式(Word・TXT・Excelなど)を選べば、目的に応じて柔軟に利用できます。
高精度なOCRを使ってPDFファイルからテキストを抽出したい方は、ぜひPDFelementをお試しください。下記ボタンから無料でインストール可能です。
![]() プライバシー保護 | マルウェアなし | 広告なし
プライバシー保護 | マルウェアなし | 広告なし
5. PDF OCRやテキスト抽出に関するQ&A
ここではOCRを利用してPDFファイルからテキストを抽出する際のよくある質問をまとめました。
Q1:OCRで文字が正確に読み取れない場合の対処法は?
対処法としていくつかありますが、ここでは2つ紹介します。
1つ目は解像度を上げることです。高解像度にすることで文字の認識率が上がります。しかし、その分解像に時間がかかってしまうので注意が必要です。
2つ目はスキャンする際の向きを調整することです。文字が斜めになっていたり、文書自体が斜めになっていると正確に読み取ることが出来ません。PDFelementの中には傾き補正の機能があるので、事前に傾きを無くしてから行うことが重要です。
Q2:画像が多いPDFでもテキスト抽出できますか?
画像が多いPDFでもテキスト抽出は可能です。PDFelementでは、PDFデータを一括でOCR処理してテキストデータを抽出する機能があります。
例えば、多くの画像がある書類を一度にデータ処理をして、効率的に文字データを取り出すことが可能です。
Q3:PDFelement以外の無料OCRツールとの違いは?
違いは、機能の範囲と安全性です。
無料のOCRは、少ない画像データを処理したい方やテキスト抽出の正確性をそこまで重視しない方に向いています。ただ、PDFelementより安全性に欠ける点は注意が必要です。
一方でPDFelementは、高精度で複数の文書をOCRで編集・検索することができ、処理スピードも無料OCRツールより速い傾向にあります。大量のデータの処理が必要な方や業務の効率化を図りたい方にPDFelementはおすすめです。
作成日: 2017-03-29 17:36:07 / 更新日: 2025-10-24 17:26:46

星野
編集者






役に立ちましたか?コメントしましょう!