PDF変換の小技
OCR紹介&小技まとめ
 OCRソフトの紹介
OCRソフトの紹介 スキャン&PDF化
スキャン&PDF化 スキャンPDFの編集
スキャンPDFの編集 スキャンPDFの変換
スキャンPDFの変換 画像化のPDFデーダ抽出
画像化のPDFデーダ抽出 OCR機能活用事例
OCR機能活用事例
OCRソフトの紹介 スキャン&PDF化 スキャンPDFの編集 スキャンPDFの変換 画像化のPDFデーダ抽出 OCR機能活用事例PDF文書はパソコンやモバイル機器で文書を表示・印刷させるためのファイル形式で、テキストと画像の情報が埋め込まれています。PDFファイルにテキストとして組み込まれている文字情報の全部または部分的に取り出して、テキストエディターなどに書き出すことができます。最も簡単な方法はコピーペーストで、大抵の場合は問題なく文字だけを取り出すことができます。
もし元のファイルに組み込まれたテキストに特殊なフォントが使われていたり、フォントのデータが正しく埋め込まれていないか編集された際に破壊された場合には、正しく表示されていても文字化けを起こすことがあります。この記事では、文字化けする原因と対処方法について紹介します。
ディスプレイで正しく表示されているまたは印刷ができるのに、PDF中の文字をコピー&ペーストをすると文字化けが発生する場合があります。文字がテキスト情報としてPDFファイルに組み込まれている場合には、フォントの種類またはフォントが破壊されている可能性があります。
このような場合には、PDF編集ソフトを利用してファイルをテキストとして保存してみることができます。最新のAdobe Readerまた他の閲覧ソフトを利用すれば、PDFの文書に埋め込まれたフォントの文字がテキストファイルとしてパソコンに保存することができます。Googleアカウントを持っている方であれば、Googleドキュメント機能を利用してテキストを取り出すこともできます。ブラウザ上でGoogleドライブにアクセスしてファイルをアップロードして、右クリックして「アプリで開く」「Googleドキュメント」を選択します。Googleドキュメントを利用すれば、10ポイント以上の文字であればテキストに変換することができますが、小さな文字や一部のフォントは正しく認識できません。
PDFファイルをテキストとして保存しても文字化けが発生する場合には、文字がフォントとして組み込まれていない可能性があります。文字が画像の一部としてファイルに組み込まれている場合には、コピー&ペーストはできませんが文書ファイルは正常に印刷することができます。画像として保存されている文字をテキストデータとして取り出すためには、専用のソフトウェアのOCR機能を使用する必要があります。
「PDFelement」(PDFエレメント)を利用すれば、Windowsパソコン上でOCR機能を使用して画像として埋め込まれている文字を、テキストデータとして組み込まれたPDFファイルを作成することができます。
PDFエレメントでのOCR機能の使い方|Wondershare PDFelement
PDFelementは、スキャナーから読み込んだ文書中に含まれる画像データから文字を認識して、テキストデータとしてPDFファイルに組み込むことができるOCR機能が利用できます。OCR機能を利用してテキストを書き出す手順ですが、文書をプリントアウトしてからスキャナーにセットします。PDFelement を起動して「ツール」を選択します。「OCR処理」ボタンをクリックすると設定画面が表示されるので「スキャンして編集可能テキストに変換」クリックします。スキャンが終了したらファイル名を指定してPDFファイルを保存します。作成されたファイルには文字がテキストとして組み込まれているため、コピー&ペーストで書き出すことができます。
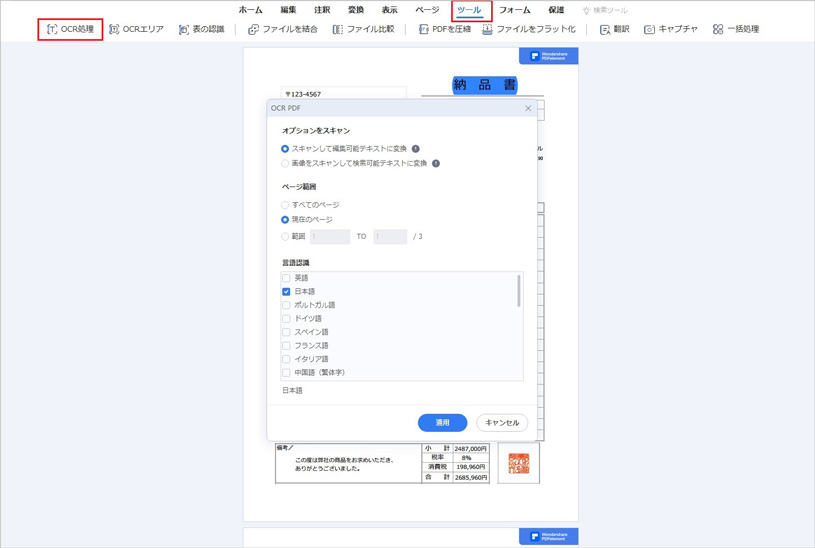
画像をPDFに変換してから、PDFelementのOCR機能を利用して画像中のテキストデータを書き出します。操作手順詳しくはOCRの使用ガイドをご参考ください。
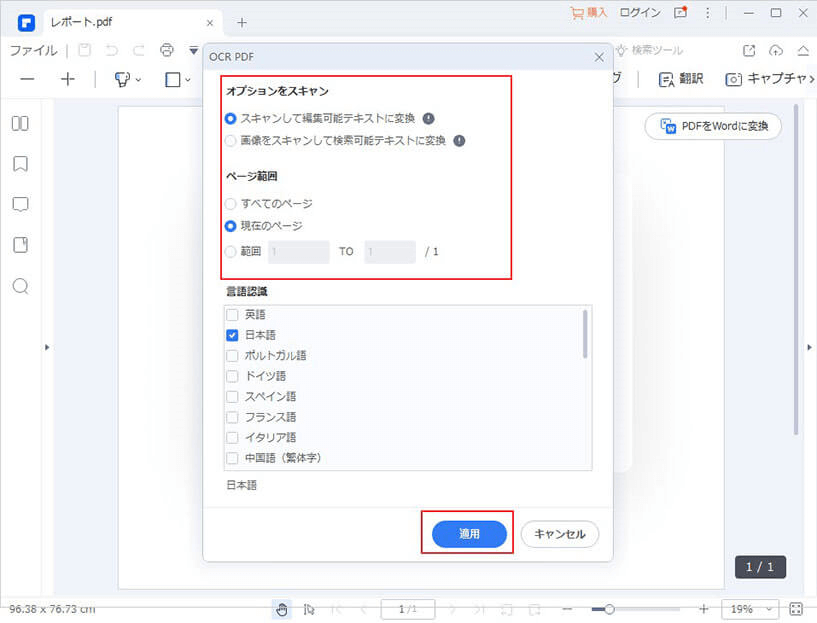
「PDFelement」(PDFエレメント)を利用すれば、PDFファイルの文字をテキストとして正しく書き出すことができない場合でもOCR機能を利用してテキストに変換することができます。PDF中に文字をコピーするときに文字化けを防ぐために、そのPDFソフトをおすすめします。 PDFelementは文字認識の成功率が高く、Googleドキュメントで正しく変換することができない場合にも利用できます。
スマートに、シンプルに、AI 搭載 PDF ソリューション
・ 第19回、24回、29回Vectorプロレジ部門賞受賞
・ 標準版からプロ版まで、幅広いのニーズに対応
・ Windows、Mac、iOS、Android、クラウドに対応
・ 7x12h体制アフターサービス
作成日: 2017-07-12 16:32:51 / 更新日: 2025-05-16 17:04:55

編集者
この文書または製品に関するご不明/ご意見がありましたら、 サポートセンター よりご連絡ください。ご指摘をお待ちしております!






役に立ちましたか?コメントしましょう!