 OfficeデータをPDFに
OfficeデータをPDFに PDF作成ソフト・方法
PDF作成ソフト・方法 写真をPDF化
写真をPDF化
 印刷物をPDF化
印刷物をPDF化Pythonは使いやすく効率的なプログラミング言語で、特にテキストや画像処理で人気があります。利用可能なライブラリの数が多いので、PythonはOCRを使って画像からテキストを抽出するなど、さまざまなタスクを自動的に実行してくれます。光学式文字認識(OCR)は、画像上に印刷された文字や手書きの文字を認識し、文字を抽出することができる技術です。
この記事では、2つの一般的なOCRエンジンの使用方法について説明していますPythonを使用して画像からテキストを抽出.


目次:
1. Pythonを使って画像からテキストを抽出する方法
Tesseractを使用してPythonの画像からテキストを抽出する
Tesseractは、100以上の言語をサポートするように事前に訓練された人気のオープンソースOCRエンジンです。この論文では、TesseractをPythonと一緒に使うことができるTesseract用のPythonラッパーであるPython-tesseract(pytesseract)を使用します。この文書に記載されている手順はすべてWindows PCで実行されます。
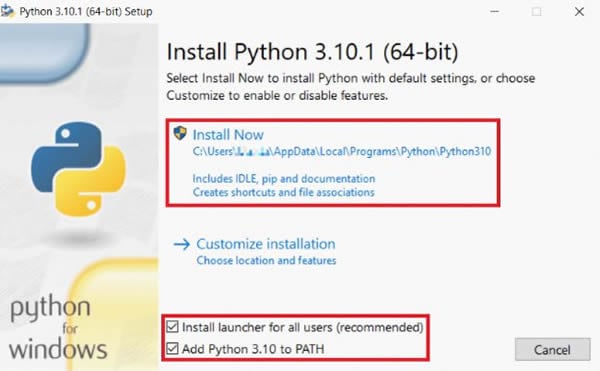
ステップ1ダウンロードしてインストールニシキヘビ.
pytesseractを使うにはPython 3.6+が必要です。だから、3.6以降のバージョンを必ずインストールしてください。次に、インストールウィンドウでパスへのPython X.XXの追加システムパスにPythonを自動的に追加します。そうでない場合は、Pythonのインストール後にシステムパスを手動で設定する必要があります。
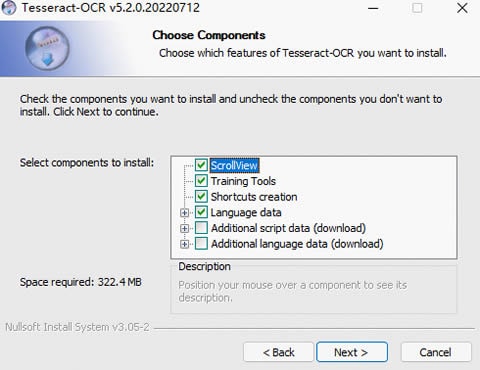
ステップ2Tesseractをダウンロードしてインストールします。
最新のインストールパッケージをダウンロードできますTesseractWindowsの場合。次に、インストールウィンドウで、インストールする追加の言語とスクリプトを選択します。デフォルトでは、英語のみをインストールできます。
Tesseractには、画像のOCRを実行する便利なコマンドラインツールが用意されています。Tesseractをインストールしたら、CLIウィンドウを開き、テキストを抽出するイメージファイルがあるフォルダに移動し、次のコマンドを実行します:
Tesseract![]() 出て行く
出て行く
このコマンドは、指定した画像からテキストを抽出し、そのテキストを出力。txtファイル。PythonでTesseractを使用するには、次の手順に進み、必要なPythonパッケージをインストールします。
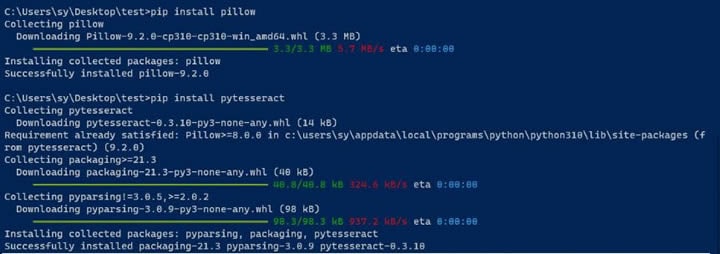
ステップ3枕とpytesseractパッケージを装着。
Pillowは画像の処理に使用され、pytesseractはPythonとともにTesseractを使用する必要があります。CLIウィンドウで次のコマンドを実行することにより、パッケージをインストールできます:
ピップ装着枕ピップ装着pytesseract
ステップ4画像からテキストを抽出するPythonコードを作成します。
これらのパッケージがインストールされたら、画像からテキストを抽出するPythonコードを書くことができます。テキストを抽出する画像ファイルが保存されているフォルダに移動します。テキストファイルを作成し、名前をに変更します抽出。ピー.テキストファイルを任意の名前に変更できますが、ファイル拡張子がpy.
メモ帳などのテキストエディタで開く抽出。ピーファイル。次のサンプル・コードをファイルにコピーして保存します:
PILからインポートImageimport pytesseractpytesseract.pytesseract.tesseract_cmd=r'C:\Program Files\Tesseract-OCR\tesseract.exe'print(pytesseract.image_to_string(Image.open('test.jpg'))
前のスクリプトを正常に実行するには、テスト。jpgと抽出。ピーファイル。本稿では以下の図を例とする。

CLIウィンドウを開き、イメージファイルが保存されているフォルダに移動し、次のコマンドを実行します:
ニシキヘビ抽出。ピー
次のコマンドが出力されます。
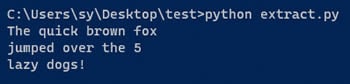
出力は、画像からテキストが正常に抽出されたことを示します。これで、PythonでTesseractを使うための基本的な手順が終わります。pytesseractの使用方法の詳細については、そのマニュアルを参照してください。
複数の画像からテキストを一括して抽出する場合は、TXTファイルにファイル名を追加すると簡単です。イメージ。txt.例:
テスト。jpgtest1.jpg
そして、修正抽出。ピーファイルは次のとおりです:
PILからインポートImageimport pytesseractpytesseract.pytesseract.tesseract_cmd=r'C:\Program Files\Tesseract-OCR\tesseract.exe'print(pytesseract.image_to_string('images.txt'))
前のスクリプトを実行すると、イメージ。txtファイル。
EasyOCRを使用したPythonの画像からのテキストの抽出
EasyOCRは、80以上の言語をサポートするすぐに利用できるOCRエンジンを提供するPythonパッケージです。EasyOCRはインストールが簡単で、非常に簡単に使えます。これはPythonを使ってOCRを実行するための良い解決策になります。PyTorch(Windowsでのみ必要)とEasyOCRパッケージをインストールするだけで、Pythonを使って画像からテキストを抽出し始めることができます。
ステップ1必要なPythonパッケージをインストールします。
WindowsでEasyOCRを使用するには、PyTorchおよびEasyOCRパッケージをインストールする必要があります。次のコマンドを順番に実行して、パッケージをインストールします:
pip取り付けフレアフレアビジョンフレアオーディオpip取り付けeasyocr
ステップ2EasyOCRを使用するPythonコードを作成します。
画像が保存されているフォルダに移動して、画像を作成します。pyファイル(例:)抽出。ピーをクリックし、次のサンプル・コードをファイルにコピーします:
import easyocrreader=easyocr.Reader(['en'])result=reader.readtext('test.jpg',detail=0)print(result)
次の図は実行を示しています抽出。ピーファイル。

コマンド出力に示すように、テキストはテスト画像から抽出されます。
2. Pythonを使うメリットとデメリット
Pythonは学習と使用が容易なプログラミング言語です。ディープラーニングや自然言語処理に幅広く活用されている。Pythonコードは通常、他の言語に比べて単純で短いです。ただし、Pythonの学習には時間がかかりますので、Pythonと一緒に使いたいOCRエンジンを調べる必要があります。
Pythonを使用して画像からテキストを抽出する利点は次のとおりです:
- Tesseract、EasyOCRなどのOCRエンジンは無料で利用できる。
- Pythonは、大量のOCRタスクと反復的なOCRタスクに適しています。
- Pythonを使って大量の画像を処理するのは効率的で高速です。
- OCRエンジンオプションtsを調整することで、音声変換結果を得ることができます。
- デザインされたPythonスクリプトを保存して、画像からテキストを抽出する必要があるときに使うことができます。同じ変換要件を持つ他のユーザーとスクリプトを共有することもできます。
Pythonを使用して画像からテキストを抽出する場合のデメリット:
- Pythonの知識が必要です。
- 使用するOCRエンジンを検討する必要があります。
- オープンソースのOCRエンジンは、商用エンジンほど正確ではない可能性があります。また、筆跡を認識できない人もいるかもしれない。
それでも、新しいことを学ぶことは常に良い。また、必要に応じていつでも別のツールに切り替えることができます。画像からテキストを素早く抽出するのに役立つ既存のツールはたくさんあります。あなたはそれを自分の希望に合わせて選ぶことができます。
3. Pythonなしで画像からテキストを抽出する方法
プログラミングの愛好家でなく、すぐに使えるツールを探している方は、PDFエレメントが速くて簡単なアプリなので、見てみるべきです。
PDFelementは、PDFの表示、編集、変換を行うことができる高速で包括的なPDFエディターです。PDFelementには、画像からテキストを正確かつ効率的に抽出するための高度なOCRエンジンも搭載されています。
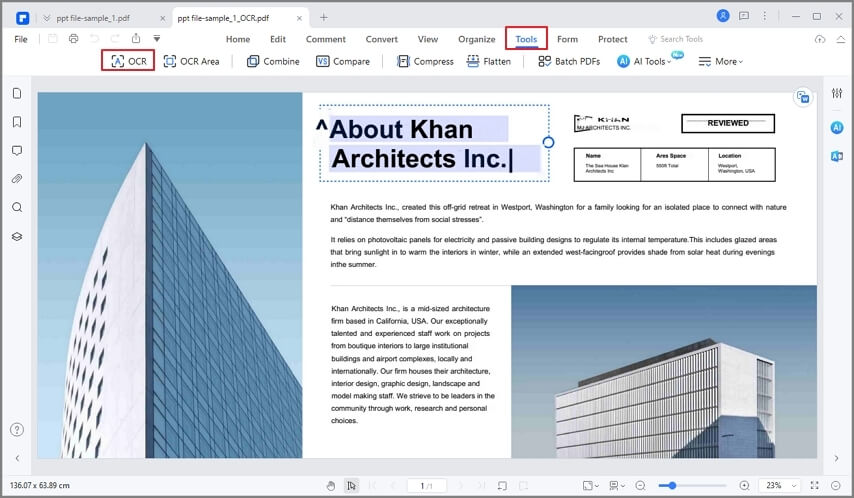
PDFelementの画像からテキストを抽出するには、次の手順に従います:
ステップ1開いているPDFelement.テキストを抽出するイメージファイルをPDFelementウィンドウにドラッグ&ドロップします。選択することもできますPDFの作成>ファイルからイメージファイルを選択します。その後、PDFelementは画像をPDFに変換し、新しいタブで開きます。
ステップ2在るツールメニューを選択してOCR画像からテキストを抽出します。これにより、PDFelementは画像内のすべての文字を認識し、編集可能で検索可能なテキストに変換することができます。
ステップ3テキストを目的の場所にコピーし、編集します。編集可能なテキストを含むPDFをWordやExcelなどの別の形式に変換することもできます。
PDFelementには、OCRエンジンに加えて、生産性を向上させるその他の機能が用意されています:
- PDFファイルをすばやく開いて表示する
- テキストや画像などのPDFファイルのコンテンツの編集
- PDFをEPUBやWordなどのさまざまな形式に変換する
結論
Pythonは、繰り返し作業を自動化するのに適した優れたプログラミング言語です。Pythonを使うことで、オープンソースのOCRエンジンを使って画像からテキストを簡単かつ迅速に抽出することができます。この文書では、Pythonを使用してTesseractとEasyOCRのOCR機能を呼び出す方法について説明します。
ただし、Pythonを使って画像からテキストを抽出するにはプログラミングが必要で、プログラミングの基本的な知識とPython言語が必要です。プログラミングの知識がなければ、画像からテキストを抽出するためのオプションは他にもたくさんあります。PDFelementは、画像からテキストを簡単かつ効率的に抽出するのに役立つ高度で複雑なアプリケーションです。








役に立ちましたか?コメントしましょう!