 PDF編集--直接編集
PDF編集--直接編集 PDF編集--透かし・背景
PDF編集--透かし・背景 PDF編集--注釈追加
PDF編集--注釈追加 PDF編集--ページ編集
PDF編集--ページ編集OCR機能を使用した PDF テキストの認識
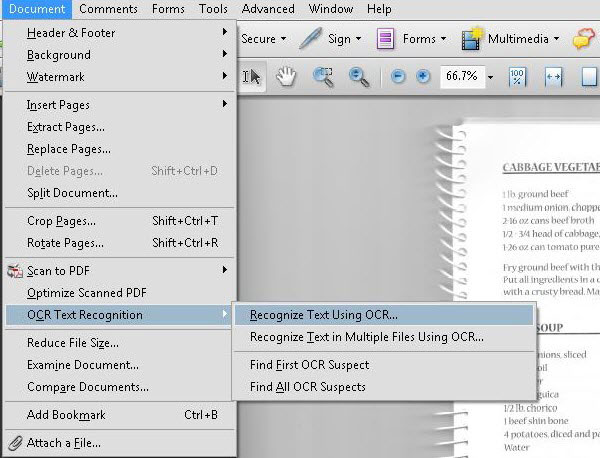
通常、スキャンした PDF 上のテキストは選択することができません。スキャンした PDF を編集するには、PDF のテキストが選択可能でなければなりません。PDF テキストを編集するには、OCR 機能を使ってまずテキストを認識させる必要があります。Acrobat 9 および Acrobat X は共に、OCR 機能が搭載されています。Adobe Acrobat 9 をお使いの場合は、[文書] > [OCR テキスト認識] > [OCR を使用してテキストを認識] と選択していきます。Acrobat X Pro をお使いの場合は、[ツール] > [テキスト認識] > [このファイル内]と選択します。
PDF EditorでスキャンしたPDFを編集
スキャンされたPDFファイルを編集可能にさせる手順を説明いたします。
Step 1: スキャンされたPDFファイルをPDFelement(PDFエレメント)に取り込みます;
PDF編集ソフトPDFelementをダウンロード・インストールします。
PDFelementを立ち上げ、スキャンされたPDFファイルを取り込みます。そしてソフトが自動的にスキャンされたPDF形式を検出してくれます。
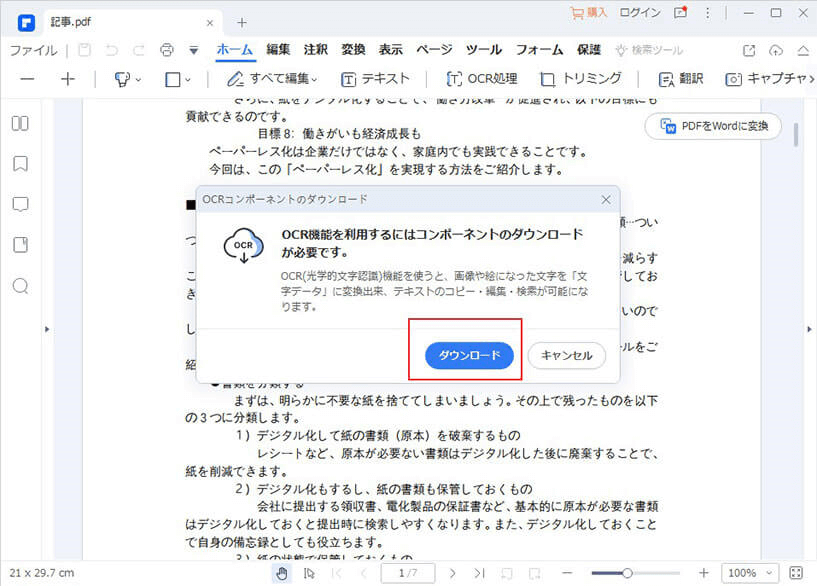
「スキャンされたPDFを検出しました。スキャンされたPDFからコピー、編集、テキストを検索するためにはOCR機能をご利用ください。」のメッセージが表示されます。
Step 2: OCRプラグインをインストールし、OCR処理を始めます;
「OCRを実行します」をクリックし、OCRプラグインをダウンロード、インストールします。
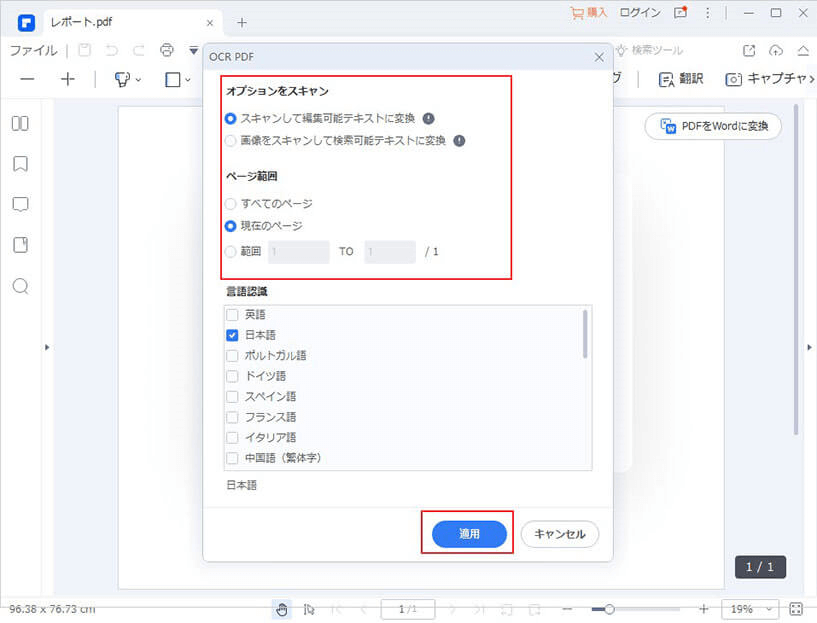
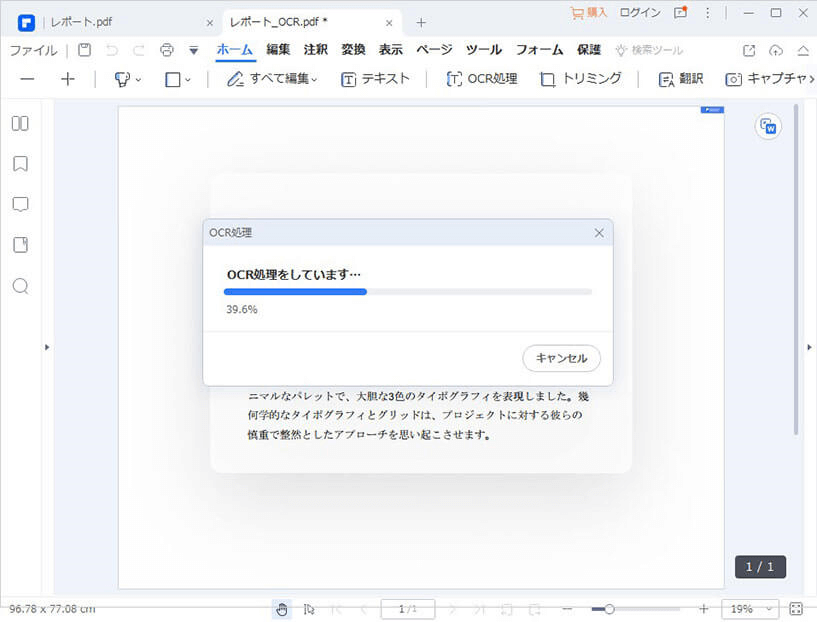
OCR機能が立ち上がったら、「言葉を変更」メニューで「日本語」を選択し、「次」をクリックすると、OCR処理が始まります。
OCR処理が完了後、もともとスキャンされた編集不可のテキストも画像も、編集できるようになります。
 OCR処理とは?
OCR処理とは?
OCRとは「光学式文字認識」の略で、OCR処理とは画像データ上にある文字と思われる部分を解析し、コンピューター上で扱える文字(テキスト)データに変換すること。
PDFelement(PDFエレメント)にOCRプラグインが搭載されているから、スキャンしたPDFを即座に編集可能なテキストに変換できます。
*元のファイルの汚れ/傾き/位置ずれなどの状況があるため、OCR処理の精度が必ず100%と保証できないのがOCR業界の現状です。
OCR処理が終わったら、元のファイルと比べて、認識ズレのところを調整しましょう。
Step 3: OCR処理、調整
以上、PDFelement(PDFエレメント)のOCR処理、スキャンされたPDFファイルを編集する方法と心得を紹介いたしました。
たった3ステップでできる編集作業で、今回のプレゼンが上手く行けて、大変助かりました。仕事で同じケースにあった方も、ぜひ試してみてください。







役に立ちましたか?コメントしましょう!