 OCRソフトの紹介
OCRソフトの紹介 スキャン&PDF化
スキャン&PDF化 スキャンPDFの編集
スキャンPDFの編集 スキャンPDFの変換
スキャンPDFの変換 画像化のPDFデーダ抽出
画像化のPDFデーダ抽出 OCR機能活用事例
OCR機能活用事例はじめに
Q:OCRいったい何ですか?
A:Optical character recognitionの略です。 印刷された活字、手書き文字を認識し、テキスト化(文字コード)に変換する仕組みを言います。

目次:
OCRを利用するときの設定には何が必要
OCRという物は光学文字読取装置の略です。画像データ上にある文字らしいものを認識する装置で、PDFのような画像データとして表現しているような場合、文字認識をする場合には、このOCRがよく利用されます。
文書言語を設定すれば、OCRが正しく画像データの中からテキストを読み取ることが出来ます。
OCR機能は、スキャナーやカメラなどで取得したデジタルデータの中から文字だけを認識してから抽出するものですが、その正確性は非常に高くなってきています。
OCR機能自体が画期的な機能で、たくさんPDF編集ソフトが世の中に出てきていますが、OCR機能を搭載しているPDF編集ソフト自体が限られていて、価値があるのです。
画像化された文章から文字の部分を勝手に認識してくれて、文字を拾い出してくれるのです。
そんな便利な機能があれば、どんな文章でも編集が出来るのではないでしょうか。
ただ、OCR機能は、正解率によっても使い物にならない場合がありますので、その点もしっかりと認識してどのOCRを利用すると画像PDFを利用することが出来るのかを決める判断材料にもなります。
特に画像PDFをよく利用する人には画期的な機能です。OCR機能があるPDF編集ソフトの中でも、おすすめなのはPDFelement Proがあります。
PDFelement Proは他のソフトに比べても信頼性があり、高確率でテキストを拾い出してくれる優秀なソフトです。
読み込めないものは何もないといえそうなPDFelement Proではないでしょうか。
どんなPDFファイルでも読み込んで編集することが出来ます。
動画から学ぶ:PDFelementのOCR機能紹介!スキャンしたPDFも編集可能!
事前に文章の日本語化を準備する
OCRを利用するときに事前に準備しておかなければならないのは、文章の日本語化です。
日本語を使用できなければ、今回のOCRを利用してから収集することが出来るのではないでしょうか。
日本で利用するときには日本語化が必要でしょうし、英語圏で利用するときには英語化が必要です。
OCRを利用するときに、まずは言語の設定を行わなければ、何も始まりません。
PDFelement ProのOCR機能を利用する時の文書言語設定
PDFelement Proを利用して方、スキャンして作成したPDFファイルを読み込んでから編集をする場合、読み込む時に画像データであるということの確認画面が表示されます。
画像PDFファイルを読み込むときに、上部のメニューバーにあるOCRボタンをクリックしてからPDFファイル全体のOCR処理を行います。
そうすると数分間の認識を行ってくれてから、編集でき状態に変更されます。実はこのOCR処理を行うときに、言語設定をしっかりと行っておく必要があります。
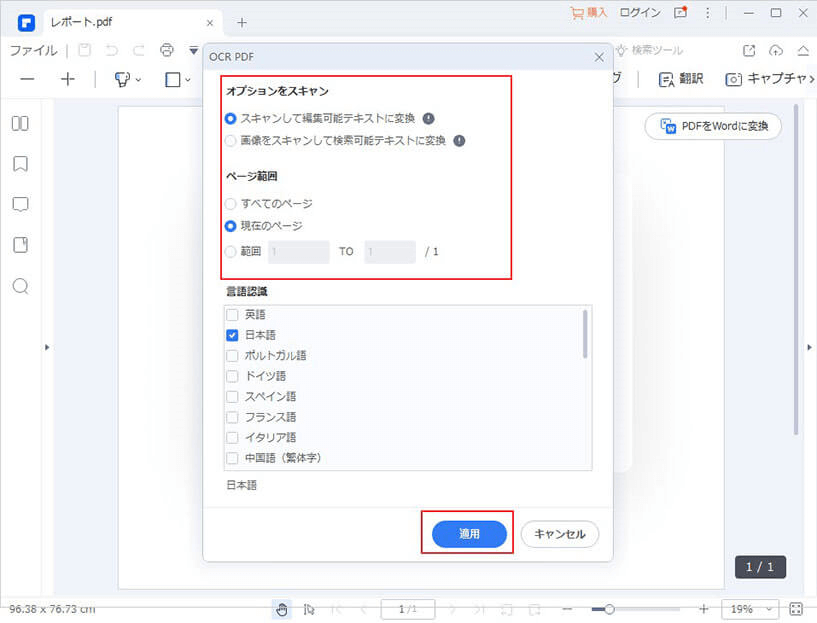
今回は日本語のPDF画像データを取り込むわけなので、OCR処理を行う前に言語設定で日本語を設定しなければいけません。そうしないとOCR読み込み処理がうまく動作しません。
日本語・英語を初めとして25か国の言語をサポートしていて、PDFelement Proならではの対応能力を誇っています。
OCRを読み込む前に言語を日本語に設定してから読み込むことで、画像イメージのPDFファイルが編集可能のPDFファイルへと変換されます。
そのときの、文字の変換率は非常に高くなっていて、利用するのには適しているOCR機能です。
別途プラグイン機能のOCR読み込みを使うことで、言語ごとの画像データPDFからテキストを認識して、編集可能のPDFへと変換してくれます。
PDF編集はこれ1本でOK | PDFelement
スマートに、シンプルに、AI 搭載 PDF ソリューション
・ 第19回、24回、29回Vectorプロレジ部門賞受賞
・ 標準版からプロ版まで、幅広いのニーズに対応
・ Windows、Mac、iOS、Android、クラウドに対応
・ 7x12h体制アフターサービス







役に立ちましたか?コメントしましょう!