国立国会図書館の無料OCRソフト「NDLOCR-Lite」とは?使い方や精度を解説
- ・「国会図書館が提供している『NDLOCR-Lite』っていうOCRソフトが話題だけど、具体的に何がすごいの?」
- ・「普通のノートパソコンでも使えるみたいだから、導入の仕方や使い方について詳しく教えて!」
この記事では国立国会図書館が提供している無料OCRソフト「NDLOCR-Lite」の特徴や操作方法、実際に利用してみての使い勝手について分かりやすく解説します。
記事を読めば今すぐにNDLOCR-Liteを使って、安全かつ効率的に資料のテキスト化や文字起こしが可能です。
NDLOCR-Liteは無料で手軽に使える一方で、対応言語の少なさやファイルの一括処理に時間がかかりがちといった欠点もあります。
「PDFelement」なら日本語や英語以外にも39言語以上をOCR機能で読み取れるため、NDLOCR-Liteでは難しい多言語資料のテキスト化が簡単です。無料でダウンロードできるPDFelementを利用して、多機能なOCR読み取りや閲覧・編集作業の快適さを今すぐ試してみてはいかがでしょうか。
![]() プライバシー保護 | マルウェアなし | 広告なし
プライバシー保護 | マルウェアなし | 広告なし
国会図書館が提供する「NDLOCR-Lite」は軽量で誰でも使える無料OCR
NDLOCR-Liteとは、国立国会図書館が2026年2月に公開したOCR(光学的文字認識)ソフトです画像やPDFを読み込ませることにより、そのファイル内に写っている文字を読み取ってテキストデータに変換します。
最大の特徴は高価なPCを必要とせず、手元にある一般的なノートパソコンでも高精度のOCR処理が行える点です。画像読み取りのスピードや精度を上げるために、OCRソフトはGPUが必要なケースが多いですが、NDLOCR-LiteはGPUなしでも動作します。
これにより特別な機材やデスクトップPCなどを用意しなくても、誰でも手軽に高精度な文字読み取りが行えます。
NDLOCR-Liteの主な特徴まとめ【対応OS・言語・ファイル形式など】
NDLOCR-Liteの主な特徴について、以下の表にまとめました。目的にあった使い方ができるか、事前に確認しておきましょう。
|
項目 |
詳細 |
|
対応OS |
Windows・Mac・Linux(Web版もあり) |
|
対応言語 |
日本語、英語のみ。手書きも一部認識可 |
|
入力ファイル形式 |
JPEGやPNGなどの画像ファイル、PDF |
|
出力ファイル形式 |
TXT、JSON、XML、TEI、透明テキスト付PDF |
|
一括処理 |
フォルダ内の複数画像をまとめて処理可能 |
|
ライセンス |
オープンソースで商用利用も可能(CC BY 4.0) |
|
OCR処理方法 |
外部サーバーへの通信は行わず、オフラインでテキスト化 |
|
使用料金 |
無料 |
おすすめの利用シーンとして、社内の予算データや議事録など、機密性の高い過去の紙資料のデジタルデータ化やアーカイブ化に向いています。
外部サーバーへの接続が不要なため、情報漏洩リスクを抑えつつ手軽にテキスト化できるからです。
またOCR処理は行いたいがとにかく費用を払いたくないという方、パソコン画面に写っている資料のキャプチャ・文字起こしを手軽にしたい方にもおすすめです。
関連人気記事:【無料OCR】GoogleドライブでPDFのテキスト化!使い方と注意点を解説
NDLOCR-Liteの使い方【画像やPDF資料を手軽にテキスト化】
NDLOCR-Liteを導入して、実際にテキスト化するまでの手順をわかりやすく解説します。
今回は最も操作が簡単なデスクトップアプリ版を使った方法をご紹介します。
まずは公式GitHubページからソフトをダウンロードして起動しましょう。
- NDLラボの公式GitHubのページから、「windows」など利用しているOSの名前が含まれたZIPファイルのリンクをクリックしてダウンロードします。
- ダウンロードしたZIPファイルを解凍してください。展開時にフォルダ名や保存先のパスに全角文字が含まれているとエラーが起きるため注意してください。
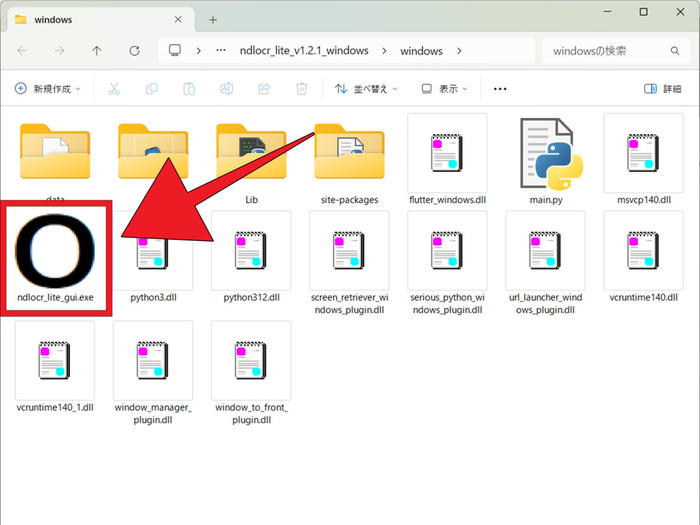
- 解凍したフォルダの中にある「ndlocr_lite_gui.exe」をダブルクリックして起動します。警告画面が現れた場合も、そのまま実行してください。初回起動時は立ち上がるまで20~30秒ほどかかります。
メイン画面が表示されたら、書類を読み込んでOCR処理を行いましょう。
- 「画像ファイルを処理する」を押して、テキスト化したい画像やPDFを選択してください。
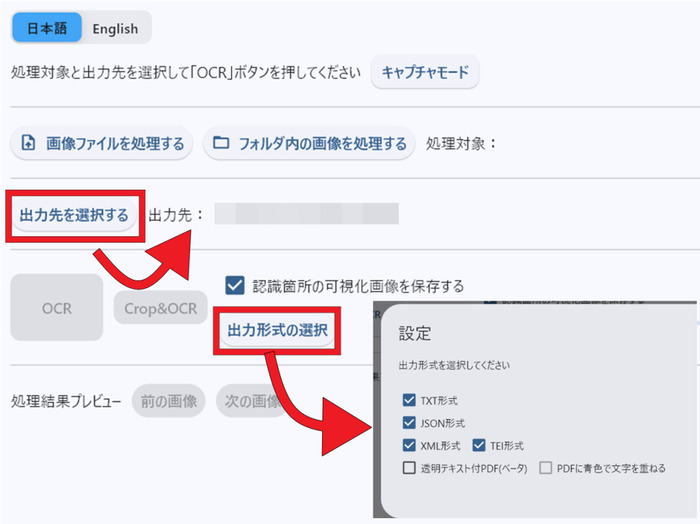
- 「出力先を選択する」ボタンでは結果の出力先フォルダを選びます。「出力形式の選択」ボタンで保存するデータのファイル形式をチェックして選びましょう。
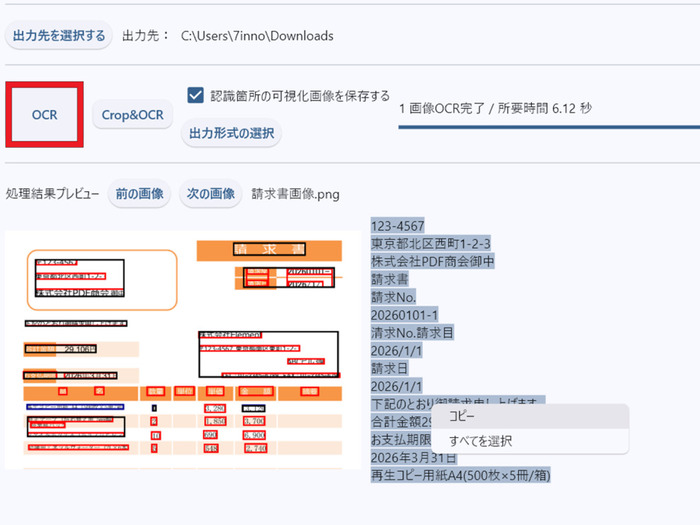
- 「OCR」ボタンを押すとOCR処理がスタートします。完了すると下部にプレビューが表示され、右側のテキスト欄の文字はそのままコピーすることが可能です。
OCR処理完了と同時に、「出力形式の選択」で選んだ形式のファイルが指定したフォルダの中に出力されます。なお複数ページあるPDFを読み込んだときは、1ページごとにテキスト化とデータ出力が行われます。
複数の資料をまとめてテキスト化する方法【フォルダ内画像の一括処理】
NDLOCR-Liteでは連続した画像ファイルや、複数のPDF文書を一度に文字起こしすることも可能です。
- テキスト化したい画像や資料のファイルは、あらかじめ1つのフォルダの中にすべて集約しておきます。
- メイン画面から「フォルダ内の画像を処理する」ボタンを選んで、上で作成したフォルダを指定してください。
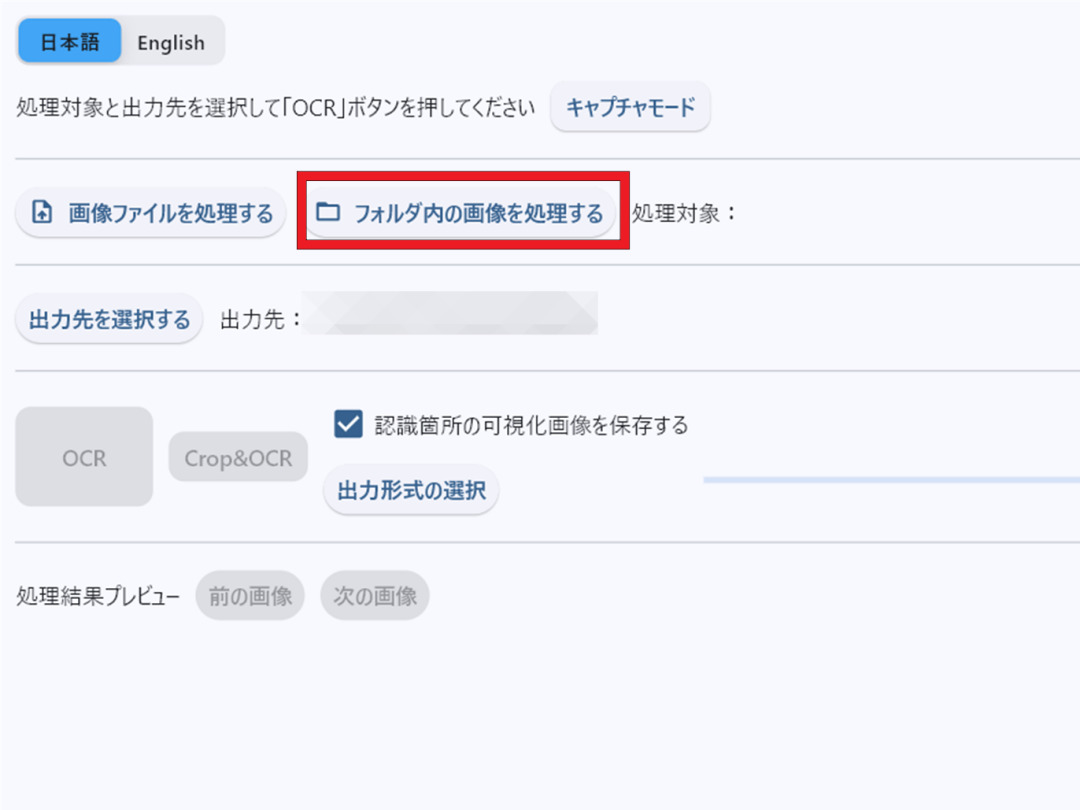
- 「出力先を選択する」「出力形式の選択」ボタンで出力先やファイル形式を指定し、「OCR」ボタンを押して処理が完了するまで待ちます。
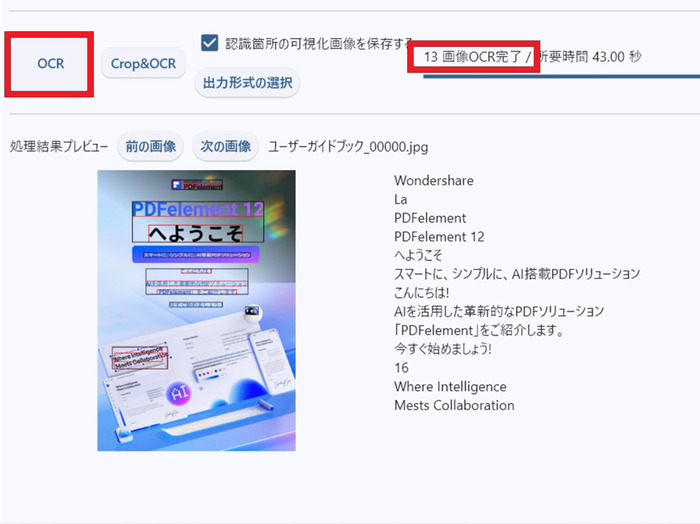
プレビューで「前の画像」「次の画像」ボタンを操作すると、各ページの文字起こし結果を順番に見れます。
なお一括処理時はフォルダ内の画像を個別に選択して処理することはできません。テキスト化したいファイルだけを対象のフォルダに格納しておきましょう。
関連人気記事:無料のOCRフリーソフトおすすめ7選!選び方・使い方を解説
資料の一部だけをテキスト化する方法【Crop&OCRモード/キャプチャモード】
文書内の任意の箇所だけを文字起こししたいときは、範囲を指定してOCR処理を行うCrop&OCRモードを利用します。
- 「画像ファイルを処理する」をクリックして文字起こししたいファイルを指定した後、「Crop&OCR」ボタンを押すと読み込んだ画像が表示されます。
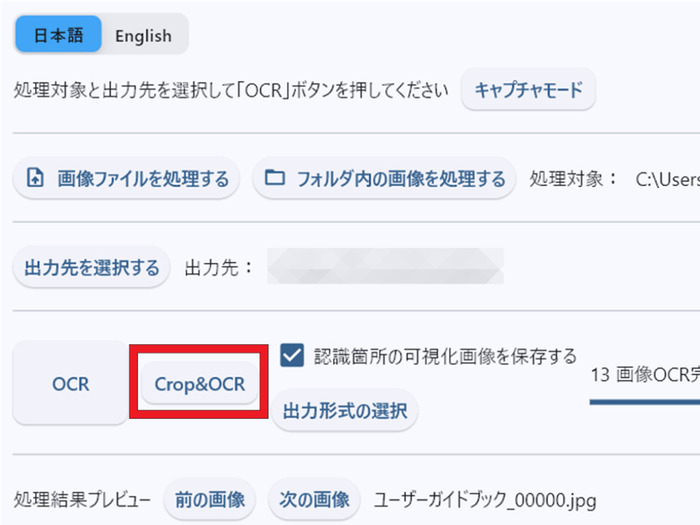
- 文字起こししたい部分をドラッグ&ドロップして青い枠で指定したら、「切り抜きOCR」ボタンを押してください。

- OCR結果が表示されるので、右側のテキスト部分をコピーして利用しましょう。なおOCR結果はテキスト形式でも指定フォルダに保存されます。

またキャプチャモードを選択すると、画像ファイルを用意しなくても、そのとき表示している画面上の範囲を自由に選んで文字起こしができます。
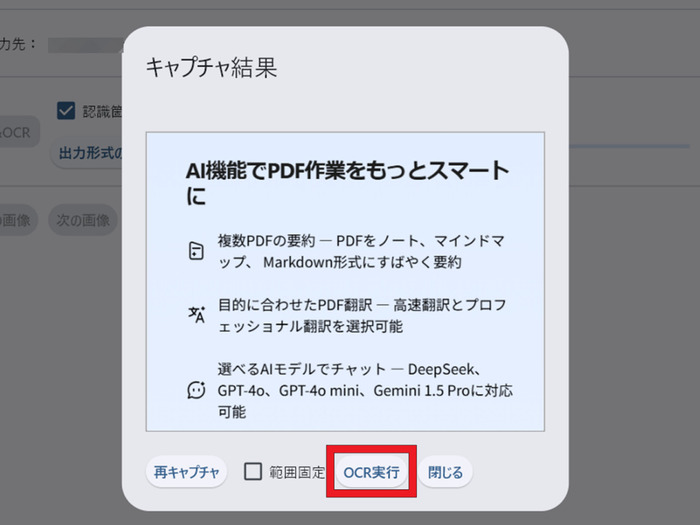
「キャプチャモード」のボタンをクリックすると、アプリの画面が一時的に消えてデスクトップ画面全体が映るので、ドラッグ&ドロップして赤い枠で範囲指定してください。
プレビュー画面でキャプチャした画像を確認し、「OCR実行」を押すと文字起こし結果が表示されるため、選択してコピーしましょう。
NDLOCR-Liteに関するよくある質問と回答
NDLOCR-Liteを使う際に、気になる点について回答します。
質問1:NDLOCR-LiteのOCR精度は高い?手書き文字の読み取りはできる?
無料ツールとしては驚くほど読み取り精度が高く、活字であれば概ね90%以上は正しくテキスト化が可能です。
特に既存のOCRではほとんど読み取れなかった、明治時代から昭和初期にかけての古い書籍でも高い精度で認識できるのが最大の特徴といえます。
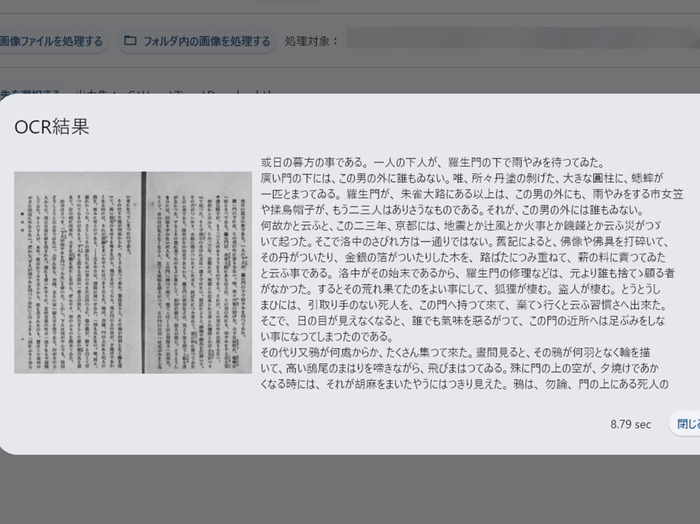
芥川竜之介 著『羅生門』,新潮社,大正12. 国立国会図書館デジタルコレクション(参照 2026-05-10)
また、手書き文字のテキスト化は実験的な機能であるためところどころに誤字はあるものの、比較的実用的な精度で読み取ってくれます。
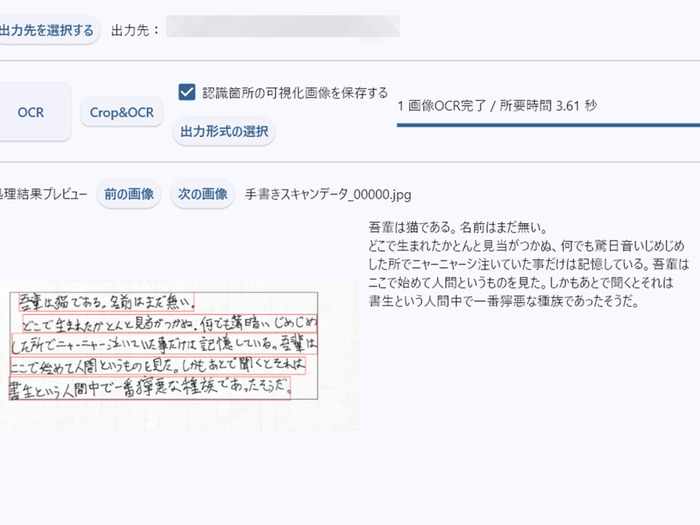
質問2:NDLOCR-Liteで読み取り対応している言語は?
現在対応している言語は「日本語」と「英語」のみです。ただし英文と手書き文字については実験的な対応とされています。
読み取る際に日本語と英語が混ざっていても問題ありませんが、これ以外の言語を読み込ませても、無理やり日本語や英字として誤認識されてしまいます。
さらに幅広い言語のテキスト化をしたい方は、次に紹介する「PDFelement」を使ってみるのがおすすめです。
質問3:iPhoneやAndroidスマホでも利用できる?
デスクトップアプリ版はパソコン専用ですが、ブラウザで動かせるように改良されたWeb版を使えば、スマホからでもテキスト化が可能です。
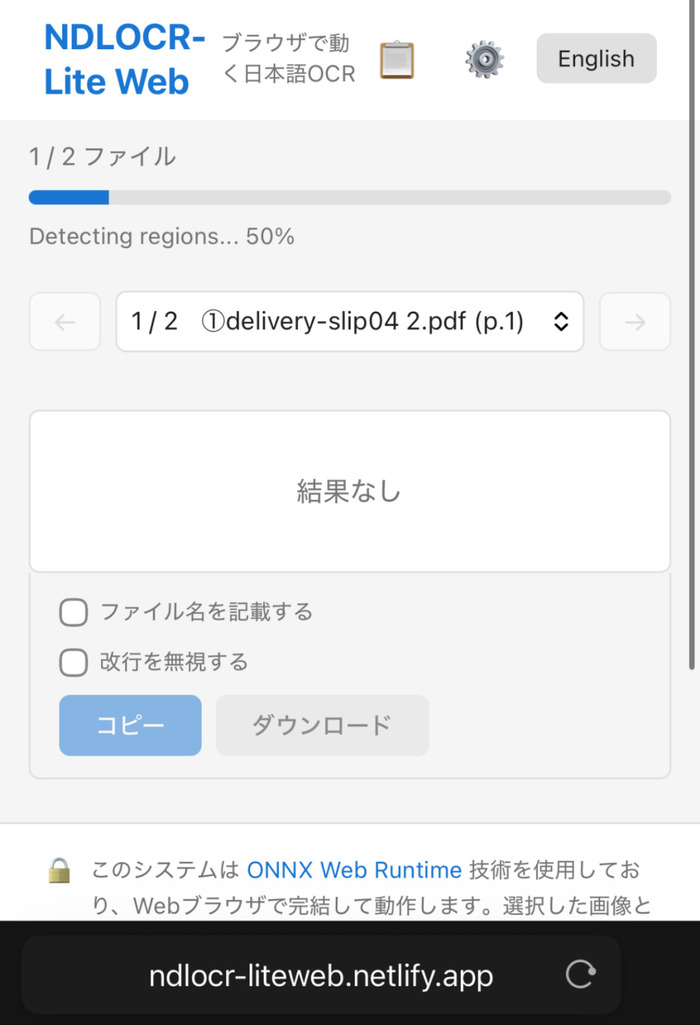
デスクトップアプリ版よりも軽量かつインストール不要で利用できますが、処理速度はやや落ちています。
なお初回起動時に約146MBのモデルのダウンロードが行われます。通信容量に上限のある格安SIMなどをお使いの方は、制限にかからないよう注意してください。
一度モデルのダウンロードを行えば、画面右上の設定から消去しない限り、同じブラウザからオフラインで利用可能です。
質問4:セキュリティ面は安全?機密情報を読み取らせても問題ない?
NDLOCR-Liteのテキスト化処理はすべてパソコンの中で完結するため、データは外部に送信されません。そのため社外秘の資料や個人情報が載っている文書なども、安全に文字起こしを行えます。
さらに上記で紹介したWeb版でも、同様にブラウザ内で処理を行っておりこちらもセキュリティ面は安全です。
ローカル処理を行う分、どちらも150〜300MBほどのアプリのインストールやモデルのダウンロードが必要となる点は気をつけましょう。
質問5:読み込めるファイルサイズや、ページ数に上限はありますか?
明確に定められたファイルサイズやPDFのページ数に制限はありません。ただしあまり多くのページ数を一度に読み込ませると処理に時間がかかります。
例えば30ページほどの画像を読み込ませると、処理が完了するまで2分ほどかかりました。
処理中は多くのメモリ容量を消費するため、他のパソコン作業が重たくなるなどの支障をきたす場合もあります。したがって大量の資料を文字起こししたいときは、テキスト化中はそれ以外の作業を止めるか、より高性能のソフトを利用しましょう。
多言語資料のテキスト化やPDF編集もしたい場合は「PDFelement」がオススメ!
NDLOCR-Liteは無料で利用可能な便利ツールではありますが、「多言語に対応していない」、「読み取ったPDFを直接編集できない」という弱点があります。
この弱点を補うためには、PDFに関するあらゆる作業を一つでこなせるソフト「PDFelement」がおすすめです。
中国語やスペイン語などで書かれた資料を読み取ったり、テキスト化したPDFの文字を編集・翻訳したりしたい場合は、PDFelementを使うと効率よく作業を行えます。
![]() プライバシー保護 | マルウェアなし | 広告なし
プライバシー保護 | マルウェアなし | 広告なし
PDFelementのOCR機能について、NDLOCR-Liteと比較してみましょう。
|
項目 |
NDLOCR-Lite |
PDFelement |
|
対応言語 |
日本語・英語の2ヶ国語のみ |
日本語・英語を含む39言語以上 |
|
OCR速度 |
1ページあたり約3~5秒 |
1ページあたり約2.5~5秒 |
|
元のレイアウト保持 |
不得意(TXT等での出力が主) |
得意(画像や表の配置を正確に維持) |
|
OCR処理後ファイルの直接編集 |
不可(透明テキスト付与のみ) |
可能(テキストや画像を直接修正・追加) |
幅広い言語にも対応していることや、編集や翻訳などによって資料を再活用できる点から、特にビジネスシーンにおいてはPDFelementの方が優秀です。
テキストの抽出に特化したNDLOCR-Liteとは異なり、複数のツールを行き来しなくても、PDFelementだけでスムーズな作業が可能になるからです。
PDFelementでは無料で使い勝手を試せるトライアル版が提供されています。OCR機能の精度やそのまま編集する便利さをぜひ体感してみてください。
PDFelement OCRを使って資料をテキスト化する手順
では実際にPDFelement OCRを使ってPDFや画像から文字起こしする方法を紹介します。複雑な操作や設定は不要で、PCでもスマホでもインストールしてすぐに使えます
![]() プライバシー保護 | マルウェアなし | 広告なし
プライバシー保護 | マルウェアなし | 広告なし
①PC(Windows/Mac)でOCR読み取りを行う方法
パソコン版で資料をテキスト化するには、次の手順で行います。
- テキスト化したいPDFや画像ファイルをPDFelementで開いて上部に現れる「OCRを実行する」ボタンをクリックします。
もしくは左側のツールタブから「OCR処理」を選択してください。
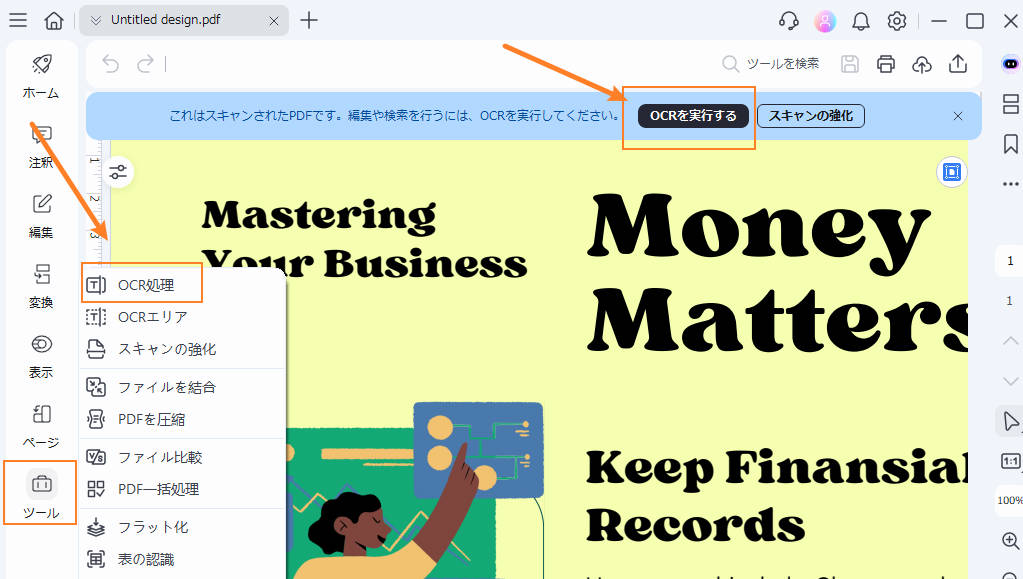
- 設定画面で認識したい言語を選び、必要に応じてページ範囲や出力設定などのオプションを調整します。
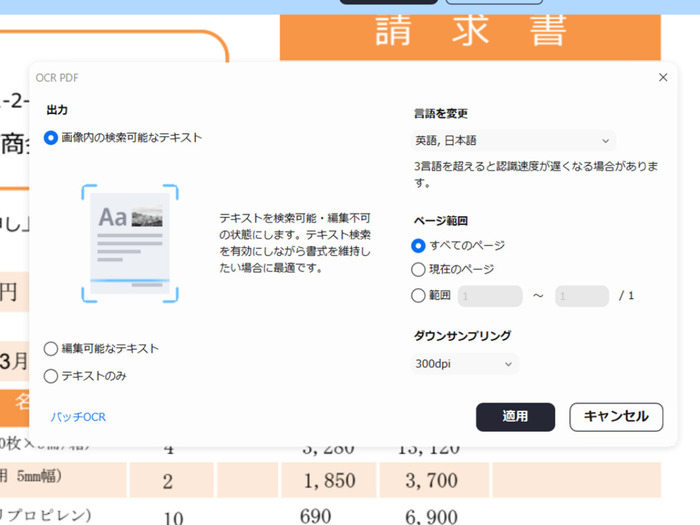
- 「適用」ボタンを押すと、OCR処理が開始します。そのままテキストのコピーや翻訳にかけることも可能です。

NDLOCR-Liteのようにテキスト抽出や検索可能なPDFに加工できるほか、編集可能なPDFとして出力することで、資料の再利用が行えます。例えば過去の契約書や請求書の日付や金額だけを書き換えて再利用するなど、一から資料を作り直す手間が省けて効率的です。
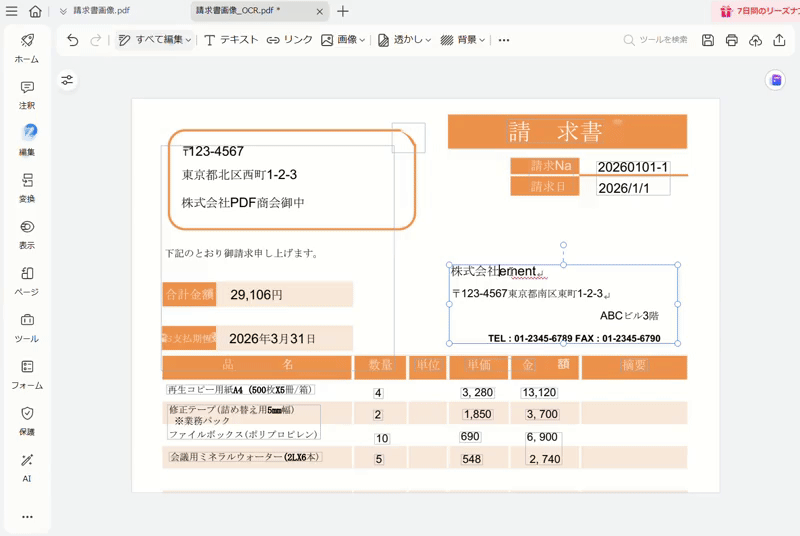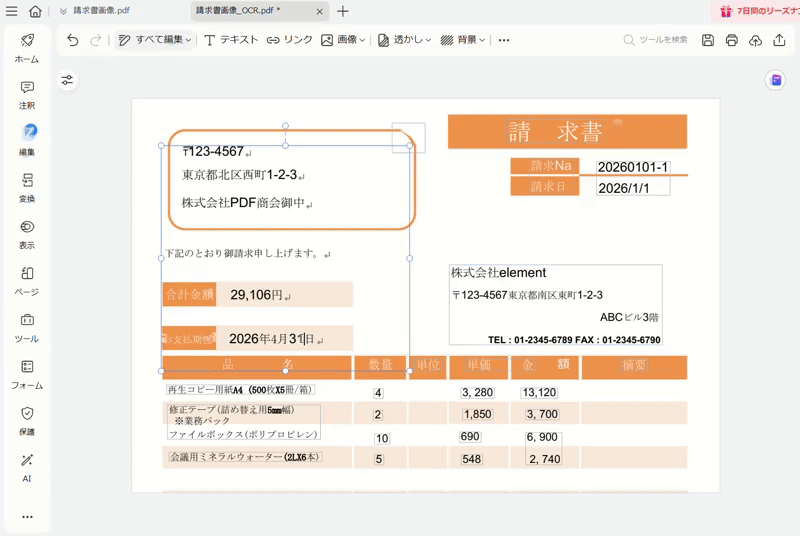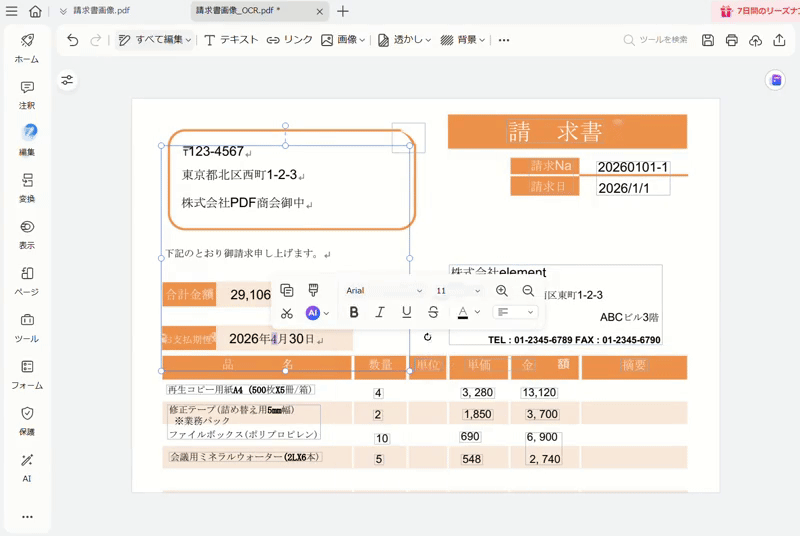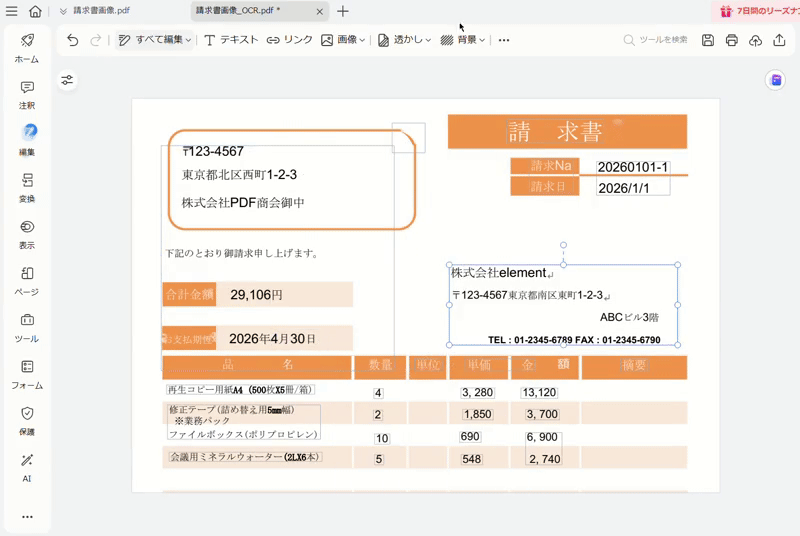
![]() プライバシー保護 | マルウェアなし | 広告なし
プライバシー保護 | マルウェアなし | 広告なし
②スマホ(iOS/Android)を使ってテキスト化を行う方法
PDFelementにはiPhone・iPadなどのiOSデバイスや、Androidスマホに対応した専用のアプリも用意されています。
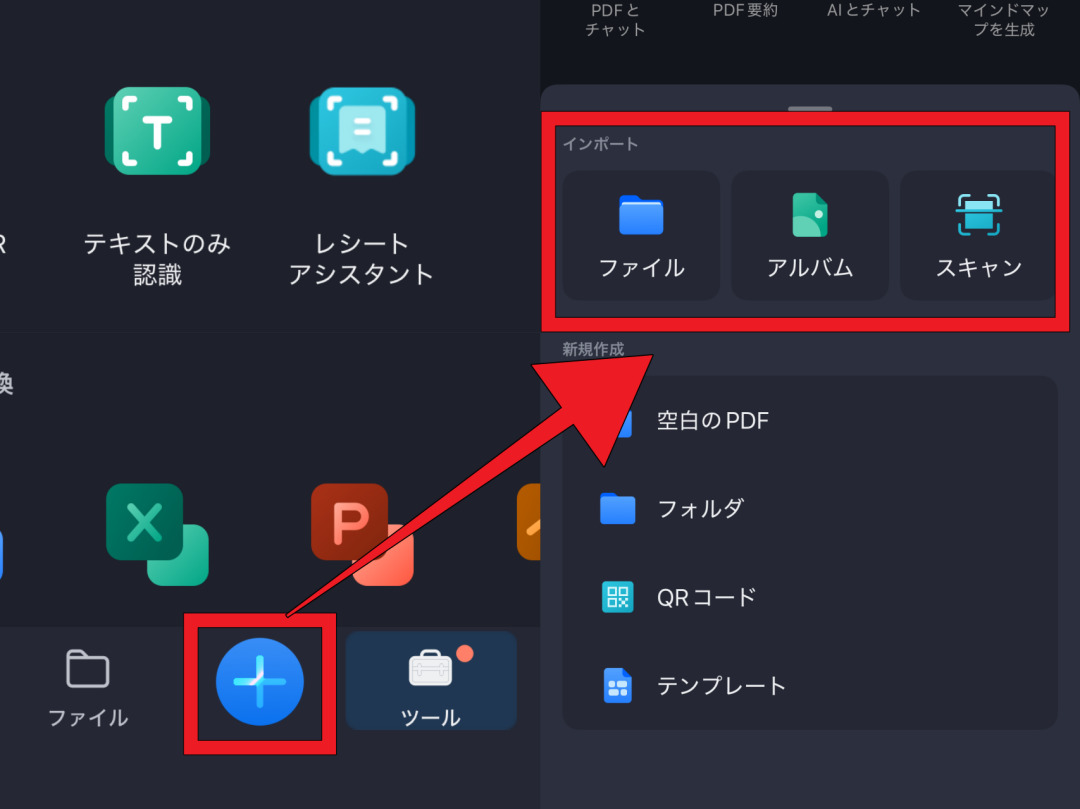
- アプリ版PDFelementをスマホで開き、画面下部の「+」ボタンからファイルを開きましょう。
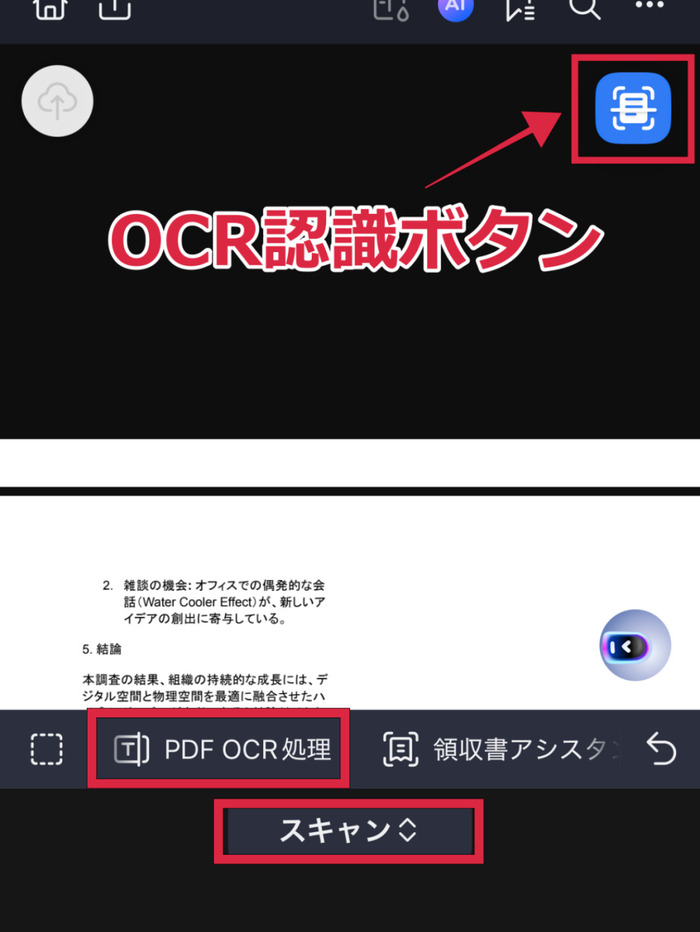
- 文字データが埋め込まれていないファイルを開くとOCR処理を行うかを尋ねるポップアップが表示されます。もしくは右上に表示される「認識」ボタンや、下部メニューの「スキャン」タブから「PDF OCR処理」をタップしてください。
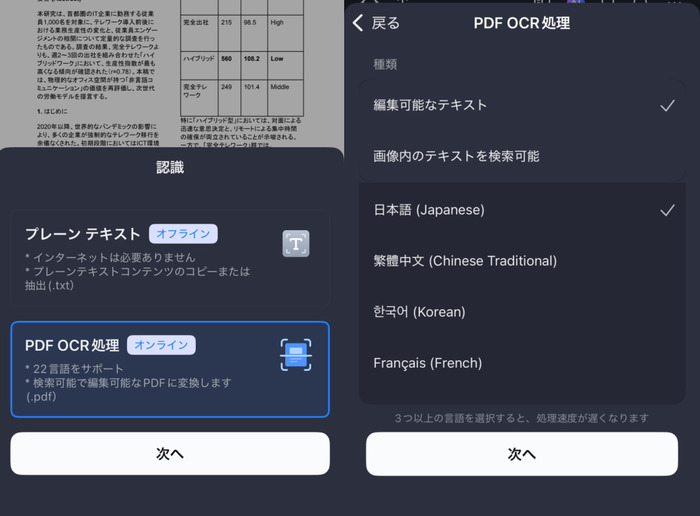
- 言語や設定を選んでOCR処理を実行します。パソコン版と同じように、多くのオプション設定が可能です。
![]() プライバシー保護 | マルウェアなし | 広告なし
プライバシー保護 | マルウェアなし | 広告なし
まとめ:NDLOCR-Liteは手軽に使える一方で多言語対応などに弱点あり
今回は、国立国会図書館が無償公開したOCRソフト「NDLOCR-Lite」の特徴や使い方などについて解説しました。NDLOCR-Liteの主な特徴は次のとおりです。
- ・GPUなしでも動作するため、一般的なノートパソコンでも使える
- ・オフラインで処理が行われるので、機密書類も処理可能
- ・日本語の活字に強く、ほぼ正確に読み取れる
ただし実際に使ってみると、次のような弱点も見受けられました。
- 日本語・英語以外は文字起こしできない
- 複数資料をOCR処理したときは、完了までやや時間を要する
- 文字起こしした資料の編集や閲覧には向いていない
そのため「英語と日本語以外の言語もテキスト化したい」、「文字を読み取った資料をそのまま編集したい」と考える方もいるかもしれません。
そんな方には、日・英以外の言語でもOCR処理を行えて、資料のレイアウトを崩さずに直接編集できる「PDFelement」が最適です。
文字起こしするだけでなく資料の作成や活用も効率的に行いたい方は、多様な機能を備えたPDFelementをぜひ使ってみてください。ダウンロードやインストールは無料です。トライアル期間を活用して、OCR機能などを存分に試してみましょう。
![]() プライバシー保護 | マルウェアなし | 広告なし
プライバシー保護 | マルウェアなし | 広告なし
作成日: 2026-05-13 09:47:07 / 更新日: 2026-05-13 11:19:21

PDFエレメント
編集者






役に立ちましたか?コメントしましょう!