ChatGPTでOCRが可能になった!PDFelementのOCRとの違いは?
近年、AI技術の進化により、OCR機能がますます身近なものになってきました。特に、ChatGPTがOCR機能を活用できるようになったことで、その可能性がさらに広がっています。しかし、従来からOCR機能を提供してきたPDFelementとの違いはどこにあるのでしょうか? 本記事では、ChatGPTとPDFelementのOCR機能を比較し、それぞれの特徴や適した用途について詳しく解説します。
目次
OCRとは?
OCRの概要
OCR(Optical Character Recognition)とは、画像やスキャンした文書から文字を認識し、テキストデータに変換する技術です。これにより、紙の文書をデジタル化したり、編集可能なテキストに変換したりすることが可能になります。
OCRの主な用途
OCRの主な用途は以下のとおりです。
・文書のデジタル化: 紙の文書をスキャンしてデジタルデータとして保存。
・テキストの編集: スキャンした文書を編集可能なテキストに変換。
・データの検索: デジタル化した文書内のテキストを検索可能に。
・自動化処理: 大量の文書を自動で処理し、データベースに登録。
ChatGPTのOCR機能とは?
ここでは、ChatGPTのOCR機能について説明します。
ChatGPTがOCR機能を活用できるようになった背景
ChatGPTは、元々自然言語処理に特化したAIモデルですが、最近のアップデートにより、OCR機能を活用できるようになりました。これにより、画像やスキャンしたPDFからテキストを抽出し、その内容を解析したり、要約したりすることが可能になりました。
どのような用途に適しているか
ChatGPTのOCR機能は、以下のような用途に使うことができます。
・簡易的なテキスト抽出: 短い文書や画像からのテキスト抽出に適しています。
・自然言語処理との連携: 抽出したテキストをそのままChatGPTで解析や要約が可能。
・リアルタイム処理: 短時間でのテキスト抽出が可能で、迅速な対応が求められる場面に適しています。
ChatGPTのOCR機能の使い方
ChatGPTのOCR機能は、以下の手順で使用します。
ステップ1. 画像またはスキャンPDFを準備
・認識したい文字が含まれる画像(JPEG、PNGなど)やスキャンPDFを用意します。
・できるだけ高解像度で、文字がはっきり読める状態が望ましいです。
ステップ2. ChatGPTに画像またはスキャンPDFをアップロード
・「+」ボタンを押して、ファイルを選択します。
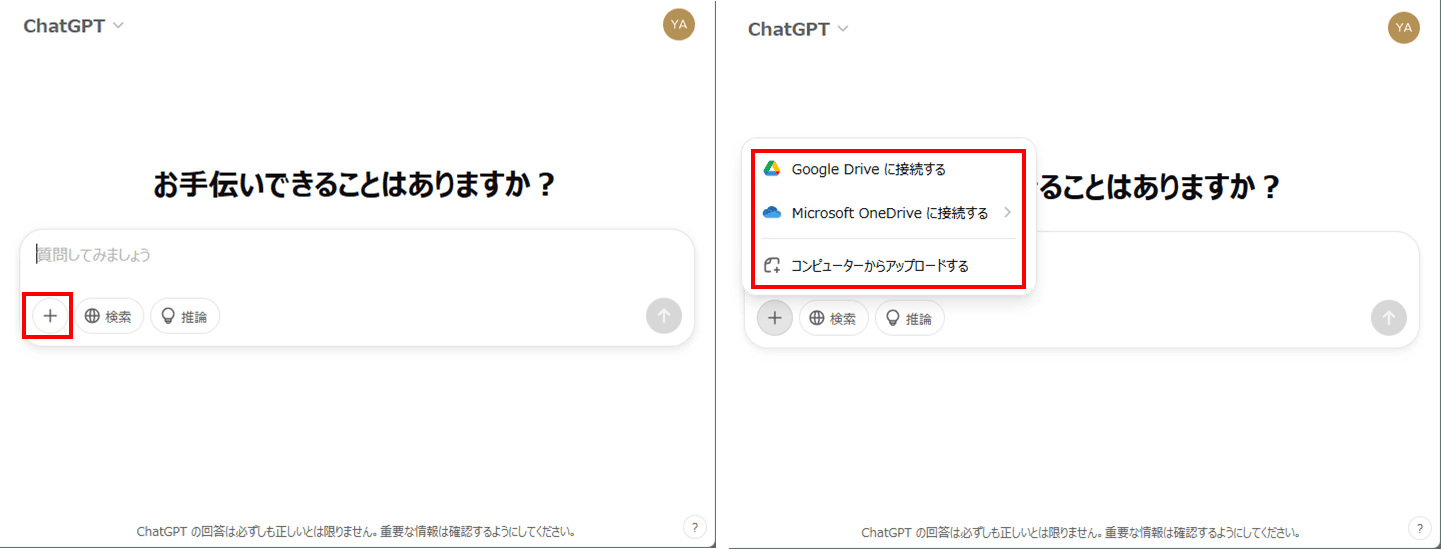
ステップ3. テキストを抽出
・「テキストを抽出してください」等と命令します。
・必要に応じて、要約や翻訳、編集などの追加処理も可能です。
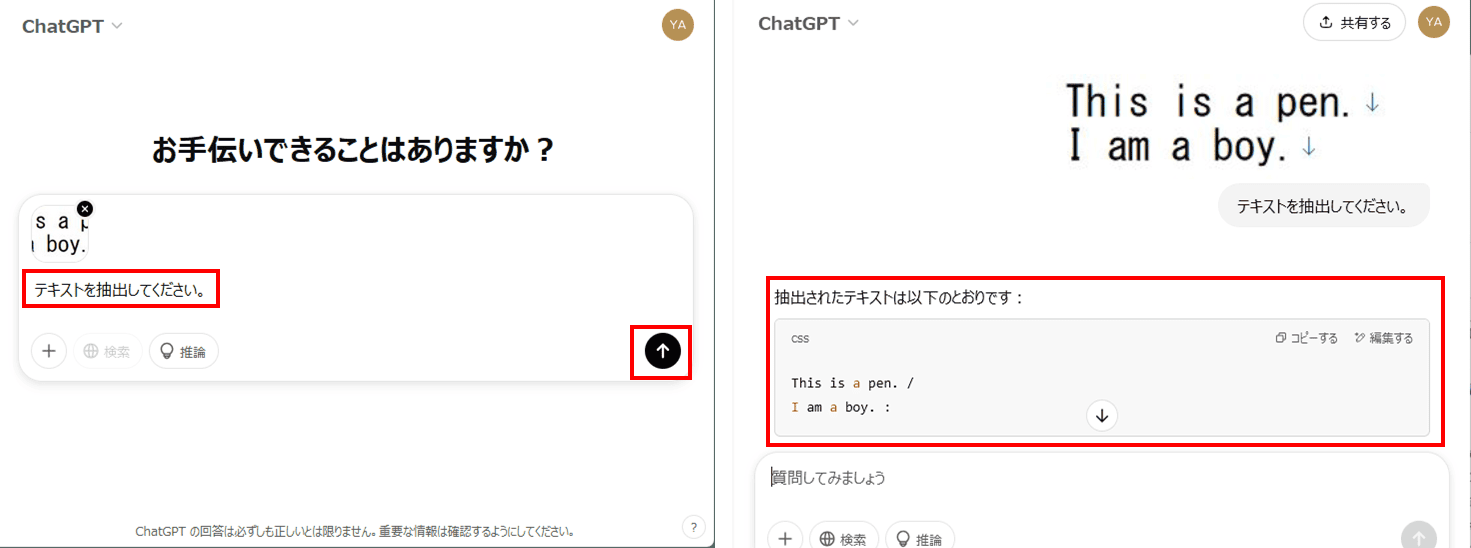
ステップ4. OCR結果を活用
・抽出したテキストをコピーして文書作成やデータ整理に活用できます。
・翻訳や要約を行う場合は、そのままChatGPTに指示を出すと処理してくれます。
制限事項
ChatGPTのOCR機能は便利ですが、以下のような制限や問題点があります。
(1) 多言語対応していない
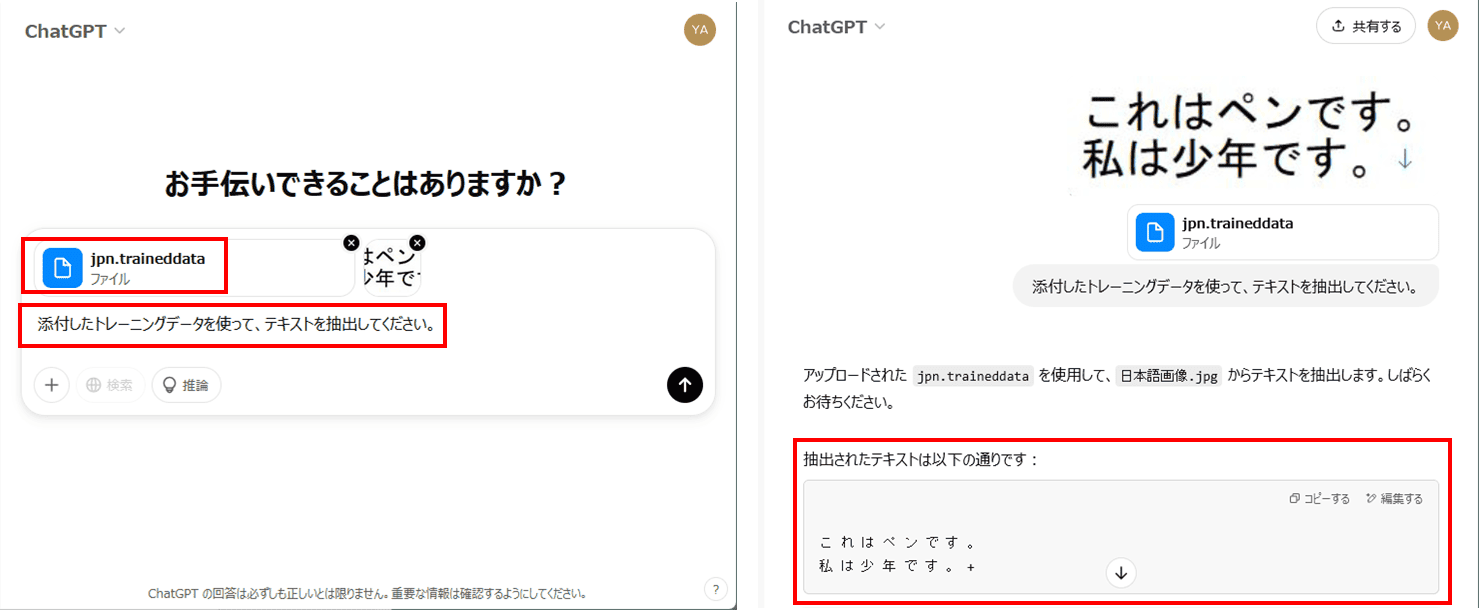
現状では、ChatGPTのOCR機能は日本語に対応していません。日本語を含む画像やスキャンしたPDFをOCR処理するには以下の手順が必要です。
- 下記のgithubページから日本語のトレーニングデータをダウンロードします。
https://github.com/tesseract-ocr/tessdata/blob/main/jpn.traineddata - このデータを画像と同時にアップロードします。
- 「添付したトレーニングデータを使って、テキストを抽出してください」等と命令します。
(2) その他の問題点
・精度の問題: 複雑なレイアウトや手書き文字の認識精度が低い場合があります。
・大量処理には不向き: 大量の文書を一度に処理するには向いていません。
・編集機能の欠如: 抽出したテキストの編集機能は提供されていません。
PDFelementのOCR機能でスキャンしたPDFを編集
オールインワンPDFelementを使えば、上記のような制限事項をカバーすることが可能となります。
PDFelementのOCR機能の特徴
PDFelementは、優れたOCR機能を持つソフトウェアで、以下のような特徴があります。
- 多言語対応:日本語を含む、 様々な言語のテキストを認識可能。
- 高精度な文字認識: 複雑なレイアウトや手書き文字も高精度で認識。
- 充実した編集機能: 抽出したテキストを直接編集可能。


スキャンしたPDFのテキストを抽出・編集する手順
以下の手順で、スキャンしたPDFのテキストを抽出・編集することができます。
ステップ1. PDFelementを起動: ソフトウェアを起動し、OCRをかけたいPDFファイルを開きます。
ステップ2. OCRを実行: ツールバーの「OCR処理」ボタン、または「OCRを実行する」ボタンをクリックし、認識させたい言語、ページ範囲を指定し、「適用」ボタンをクリックします。
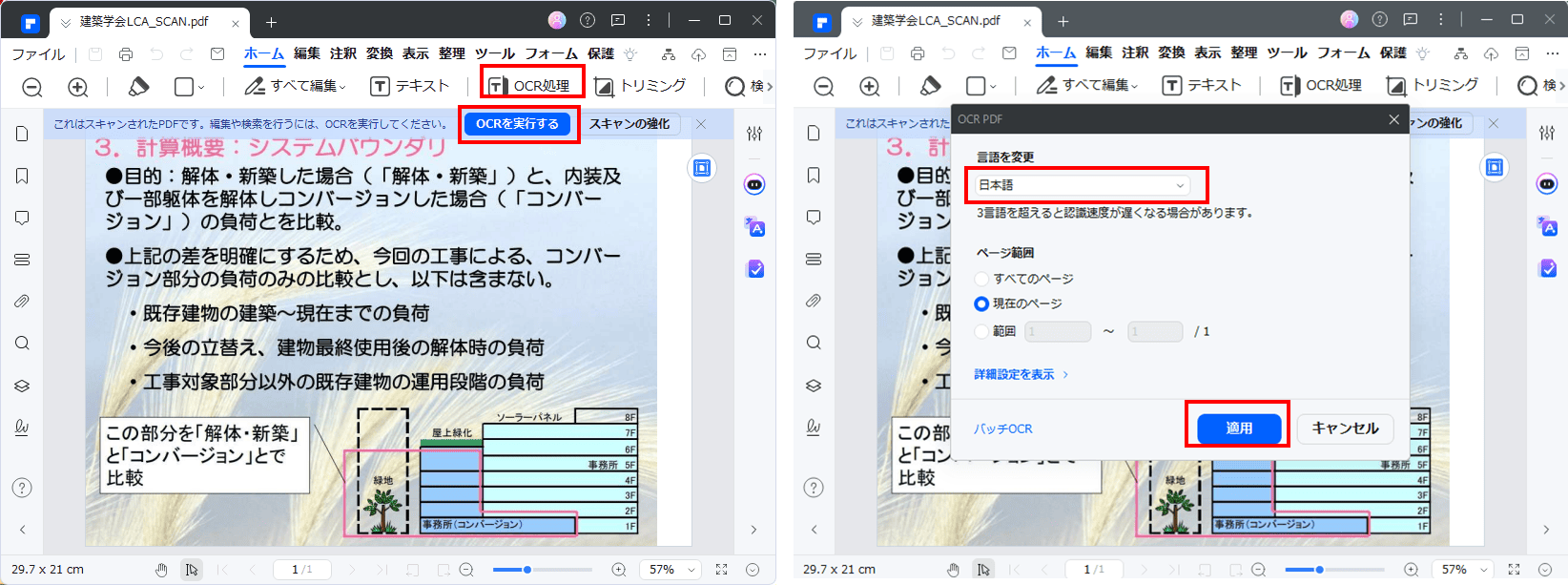
ステップ3. テキスト抽出:複雑なレイアウトのPDFでも背景やレイアウトを維持したままテキスト抽出可能なPDFに変換され、テキストを自由に抽出することが可能となります。
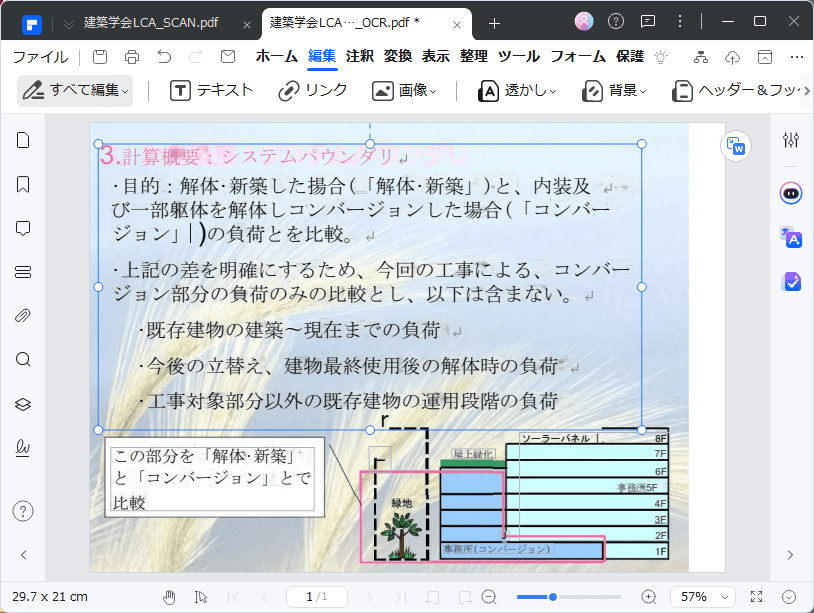
OCR後の文字修正やフォント調整のポイント
OCRは必ずしも完璧ではありません。OCR後に文字修正やフォント調整が必要になります。
- 文字修正: OCR処理後の誤認識を手動で修正します。
- フォント調整: 抽出したテキストのフォントやサイズを調整し、見やすくします。
- レイアウト調整: テキストの配置を調整し、元の文書に近いレイアウトに整えます。
ChatGPTとPDFelementのOCR機能の違い
ChatGPTとPDFelementのOCR機能の違いをまとめます。
- 多言語対応:ChatGPTは現在、日本語に対応するにはトレーニングが必要ですが、PDFelementは日本語を含む多言語に対応しています。
- 精度: PDFelementの方が高精度で、複雑なレイアウトや手書き文字にも対応可能です。
- 編集機能: PDFelementは抽出したテキストの編集が可能ですが、ChatGPTにはこの機能がありません。
- 処理速度: ChatGPTはリアルタイム処理に優れていますが、大量処理には向いていません。
- 用途: ChatGPTは簡易的なテキスト抽出や自然言語処理に適しており、PDFelementは本格的な文書処理に適しています。
OCRを活用する際の注意点
OCRは便利ですが、活用する際には以下の点に注意が必要です。
- 精度の確認: OCR処理後は必ず精度を確認し、誤認識がないかチェックします。
- データのバックアップ: 元の文書データは必ずバックアップを取っておきます。
- ソフトウェアの選択: 用途に応じて適切なソフトウェアを選択しましょう。
まとめ
ChatGPTのOCR機能は、簡易的なテキスト抽出や自然言語処理との連携に優れていますが、複雑な文書処理にはPDFelementの方が適しています。PDFelementは多言語に対応し、高精度な文字認識と編集機能を備えており、本格的な文書処理に最適です。用途に応じて適切なツールを選択し、効率的にOCRを活用しましょう。
作成日: 2025-03-12 09:54:32 / 更新日: 2025-11-07 10:15:29

PDFエレメント
編集者







役に立ちましたか?コメントしましょう!